
text_blind_watermark 文本盲水印
项目地址:https://github.com/guofei9987/text_blind_watermark
一、原理
文本盲水印将信息隐匿到文本中,不改变文本外观和可读性。
核心思路
嵌入: 水印字符串 → 加密 → 二进制 bit 流 → 在载体文本的字符间插入不可见字符
提取: 扫描文本 → 识别不可见字符 → 还原 bit 流 → 解密 → 原始字符串
- bit
1→ 在载体文本的字符后插入一个不可见字符(如chr(0x7F)或零宽字符) - bit
0→ 不做操作,只移动到下一个字符
二、v0.4.2 用法(最新版,推荐)
安装
1pip install text_blind_watermark
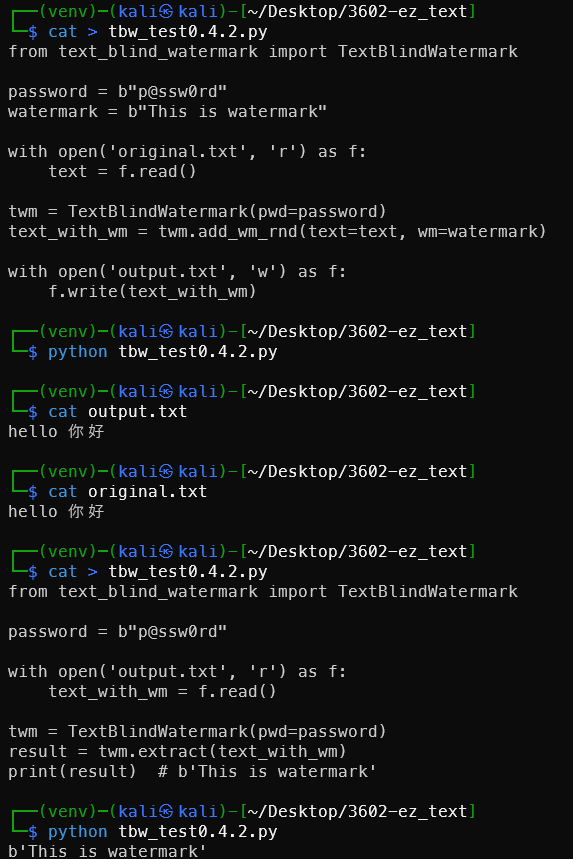
嵌入
1from text_blind_watermark import TextBlindWatermark
2
3password = b"p@ssw0rd"
4watermark = b"This is watermark"
5
6with open('original.txt', 'r') as f:
7 text = f.read()
8
9twm = TextBlindWatermark(pwd=password)
10text_with_wm = twm.add_wm_rnd(text=text, wm=watermark)
11
12with open('output.txt', 'w') as f:
13 f.write(text_with_wm)
提取
1from text_blind_watermark import TextBlindWatermark
2
3password = b"p@ssw0rd"
4
5with open('output.txt', 'r') as f:
6 text_with_wm = f.read()
7
8twm = TextBlindWatermark(pwd=password)
9result = twm.extract(text_with_wm)
10print(result) # b'This is watermark'
技术细节
- 水印字符:
chr(0x2060)(Word Joiner) 表示 bit=0,chr(0xFEFF)(BOM) 表示 bit=1 - 加密方式:XOR(通过
CryptConverter) - 密码格式:bytes 类型,如
b"password" - 水印字符是真正的零宽字符,终端/浏览器中完全不可见
- 嵌入位置随机(
add_wm_rnd),也可以指定位置(add_wm_at_idx)
其他嵌入方式
1twm.add_wm_at_idx(text=text, wm=watermark, byte_idx=10) # 指定位置嵌入
2twm.add_wm_at_last(text=text, wm=watermark) # 末尾嵌入
三、v0.0.2 用法(AES-ECB 加密,CTF 常考)
安装
1pip install text_blind_watermark==0.0.2 pycryptodome
注意: v0.0.2 源码中
import crypto与pycryptodome的Crypto模块冲突。 安装crypto包后还需手动修复源码中的 import。 CTF 建议直接用下方的独立脚本,不依赖库版本。
嵌入
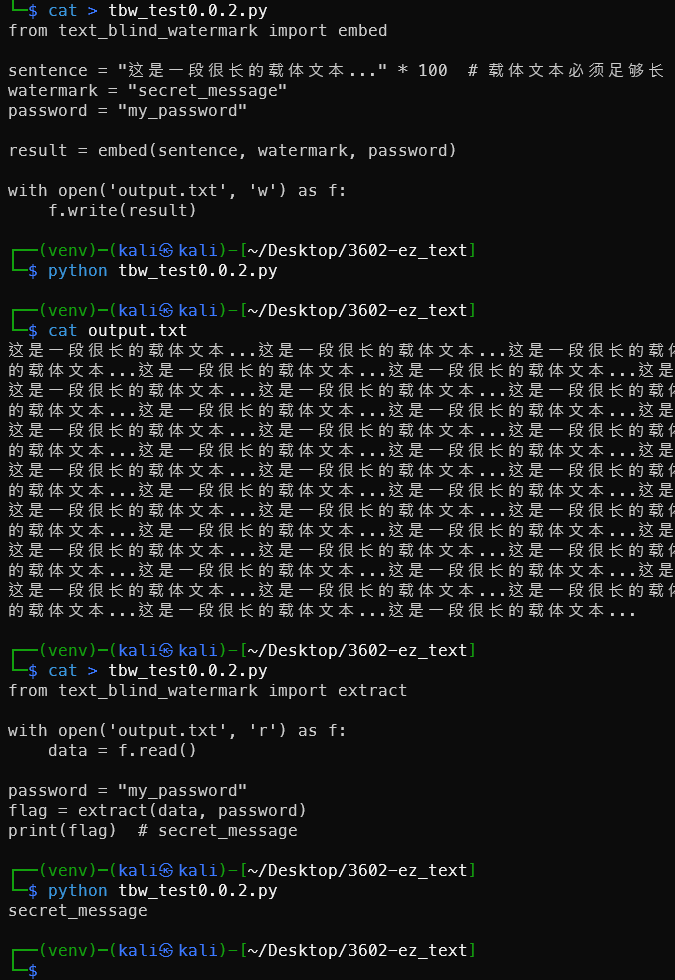
1from text_blind_watermark import embed
2
3sentence = "这是一段很长的载体文本..." * 100 # 载体文本必须足够长
4watermark = "secret_message"
5password = "my_password"
6
7result = embed(sentence, watermark, password)
8
9with open('output.txt', 'w') as f:
10 f.write(result)
提取
1from text_blind_watermark import extract
2
3with open('output.txt', 'r') as f:
4 data = f.read()
5
6password = "my_password"
7flag = extract(data, password)
8print(flag) # secret_message
技术细节
- 水印字符:
chr(127)即0x7F(DEL) - 加密方式:AES-ECB
- 密码格式:字符串类型,右补
0至 16 字节作为 AES 密钥- 如
"my_password"→"my_password00000"
- 如
- 嵌入流程:
水印 → UTF-8 编码 → AES-ECB 加密 → 十六进制 → 二进制 → 插入 chr(0x7F) - 提取流程:
扫描 chr(0x7F) → 二进制 → 对齐 128 位 → 十六进制 → AES-ECB 解密
四、版本对比
| 版本 | 安装 | 水印字符 | 加密 | 密码类型 | API |
|---|---|---|---|---|---|
| v0.0.2 | pip install text_blind_watermark==0.0.2 crypto pycryptodome | chr(127) 0x7F | AES-ECB | str | embed() / extract() |
| v0.4.2 | pip install text_blind_watermark | 0x2060 / 0xFEFF | XOR | bytes | TextBlindWatermark 类 |
五、CTF 解题
例题[[3602-ez_text]]
典型套路
- 题目给出一个嵌入水印的文件(.txt 或通过隐写工具提取的 .txt)
- 密码可能藏在文件尾部、文件名、题目描述中
- 识别出
text_blind_watermark库,判断版本,用对应算法解密 - 输出可能是 hex 编码,需要再做一次 hex decode
万能解题脚本(不依赖库版本)
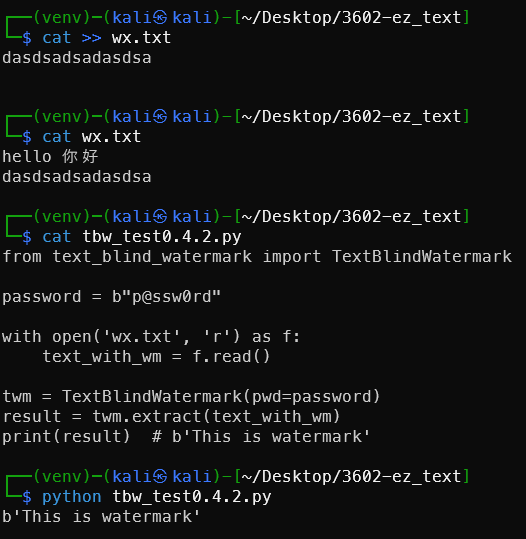
适用于 v0.0.2 的 AES-ECB 算法,不需要安装 text_blind_watermark:
1from Crypto.Cipher import AES
2
3with open('text_blind_watermark.txt', 'r') as f:
4 data = f.read()
5
6password = '!@#$123456' # 根据题目修改
7
8# 1. 提取二进制:chr(0x7F) = bit 1,其余 = bit 0
9bin_wm = ""
10prev = False
11for ch in data:
12 if prev:
13 if ord(ch) == 127:
14 bin_wm += "1"
15 prev = False
16 else:
17 bin_wm += "0"
18 prev = True
19 else:
20 prev = True
21
22# 2. 去尾部零,对齐到 128 位边界(AES 块大小)
23last = len(bin_wm) - bin_wm[::-1].find("1")
24last = ((last - 1) // 128 + 1) * 128
25bin_wm = bin_wm[:last]
26
27# 3. AES-ECB 解密
28hex_str = hex(int(bin_wm, 2))
29key = '{:0<16}'.format(password).encode('utf-8')
30result = AES.new(key=key, mode=AES.MODE_ECB).decrypt(
31 bytes.fromhex(hex_str[2:])
32).decode('utf-8')
33
34print("提取结果:", result)
35
36# 4. 如果结果是 hex 编码的 flag,再解一次
37flag_hex = result.split()[-1]
38print("Flag:", bytes.fromhex(flag_hex).decode())
快速判断版本
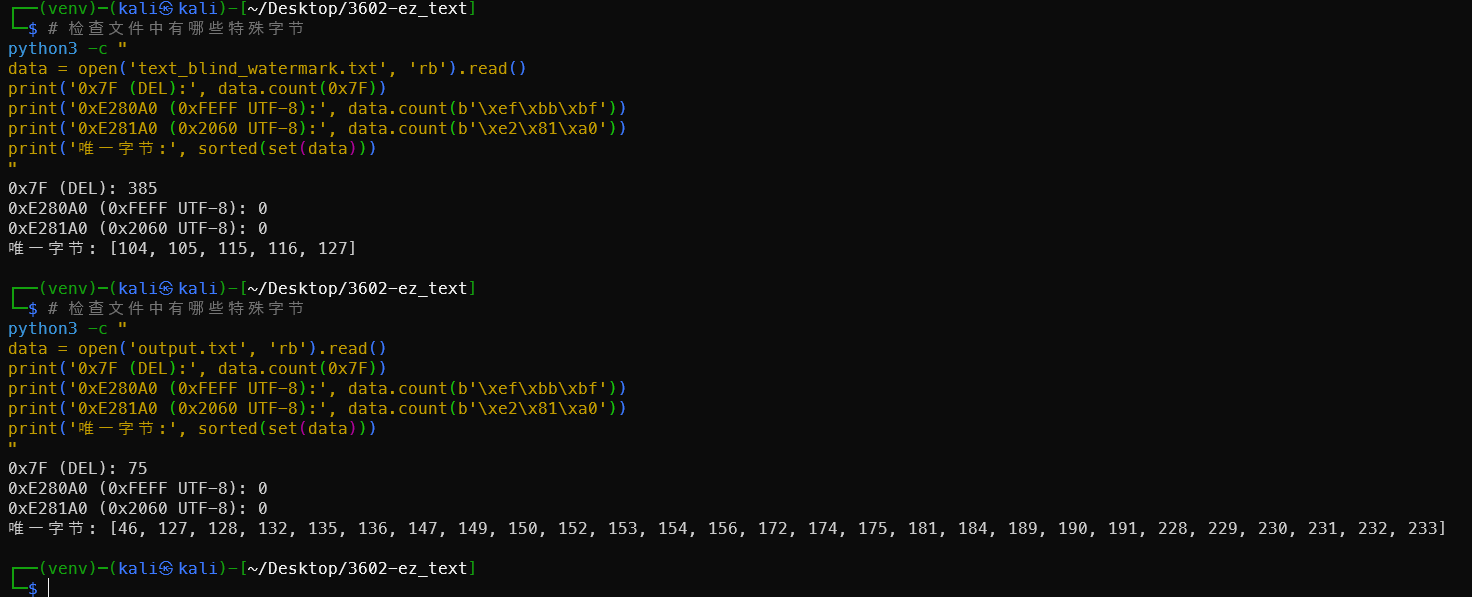
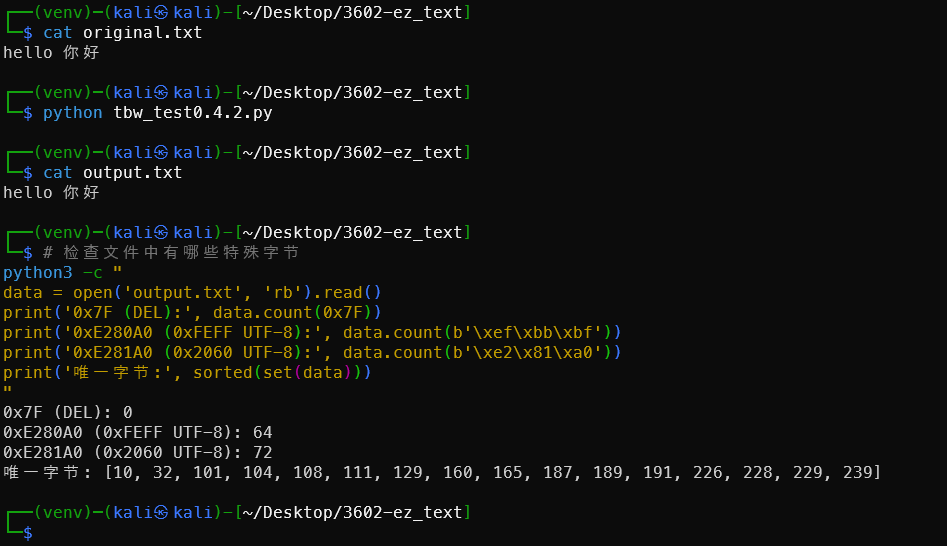
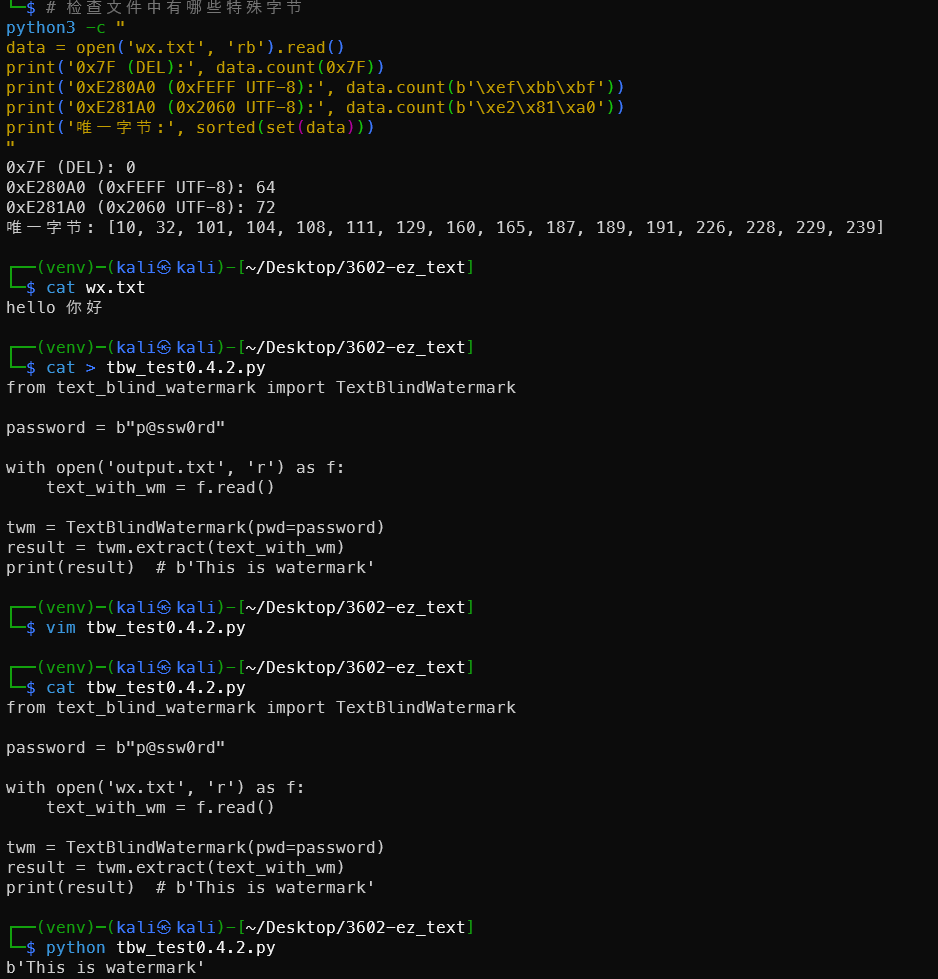
1# 检查文件中有哪些特殊字节
2python3 -c "
3data = open('text_blind_watermark.txt', 'rb').read()
4print('0x7F (DEL):', data.count(0x7F))
5print('0xE280A0 (0xFEFF UTF-8):', data.count(b'\xef\xbb\xbf'))
6print('0xE281A0 (0x2060 UTF-8):', data.count(b'\xe2\x81\xa0'))
7print('唯一字节:', sorted(set(data)))
8"
- 含
0x7F→ v0.0.2 ~ v0.3.1,用上面的万能脚本 - 含零宽字符 → v0.4.2,用
TextBlindWatermark类
六、踩坑记录
1. v0.0.2 的 import crypto 冲突(最常见)
v0.0.2 源码第一行是 import crypto(小写),但实际需要的是 pycryptodome 提供的 Crypto(大写)。
修复方法:安装后手动改源码:
1pip install text_blind_watermark==0.0.2 pycryptodome
2# 找到源码位置
3vi $(python -c "import text_blind_watermark; print(text_blind_watermark.__file__)")
4# 第1行: import crypto → import Crypto
5# 注释掉第4行: # sys.modules['Crypto'] = crypto
2. v0.0.2 的 bin() 丢前导零 bug
embed() 函数中 bin(int(hex, 16)) 会丢掉前导零。当 AES 密文首字节 < 0x10 时,二进制少一位,提取结果错位,解密出乱码。
修复方法:在源码中将:
1# embed 中:
2bin_text = bin(int(ciphertext_hex, base=16))[2:]
3# 改为:
4bin_text = bin(int(ciphertext_hex, base=16))[2:].zfill(len(ciphertext_tmp) * 8)
5
6# extract 中:
7hex_wm_extract = hex(int(bin_wm_extract, base=2))
8AES...decrypt(bytes.fromhex(hex_wm_extract[2:]))
9# 改为:
10hex_wm_extract = hex(int(bin_wm_extract, base=2))[2:].zfill(len(bin_wm_extract) // 4)
11AES...decrypt(bytes.fromhex(hex_wm_extract))
3. 密码类型不同
- v0.0.2 用 字符串:
password = "my_password" - v0.4.2 用 bytes:
password = b"p@ssw0rd"
4. 不可见字符在复制粘贴时丢失
chr(0x7F)在终端中不可见但存在- 零宽字符(0x2060/0xFEFF)复制粘贴可能丢失
- 始终直接传文件,不要复制粘贴内容
七、实际应用场景
1. 文档泄露溯源(最核心用途)
给不同人发同一份文档,每个人嵌入不同的水印(如工号、邮箱)。一旦泄露,提取水印就知道是谁泄的。
- 公司内部敏感报告、商业计划书
- 上市公司财报发给不同分析师
- 政府机密文件分发
2. AI / LLM 输出追踪
给 AI 生成的文本嵌入水印,后续可验证某段文本是否由该模型生成。DeepMind、OpenAI 都在研究这个方向。
3. 社交平台防搬运
在知乎、公众号文章里嵌入隐形水印,被人复制搬运后可举证是你的内容。
4. 企业通讯取证
在钉钉、飞书等企业通讯中,给每条消息嵌入用户标识,截图泄露后可溯源。
为什么选"盲"水印
“盲"指提取时不需要原始文本,只需密码。普通水印提取需要对比原文,盲水印只要有密码就能从被篡改过的文本里提取出来。
八、v0.4.2 复制粘贴兼容性
v0.4.2 使用零宽 Unicode 字符(U+2060 Word Joiner / U+FEFF BOM),可以跨平台复制粘贴传播。
测试通过的场景
经作者测试,以下场景水印信息隐藏比较完美:
- Chrome 浏览器(Mac),包括知乎网页版、微博网页版等
- 微信、钉钉(Mac / iPhone 均可)
- 苹果备忘录
- Chrome 打开 github.com 上的代码文件和文本文件(md 文件不行)
- 用 Ctrl+C/V 在上述平台之间复制粘贴
使用收集复制再发这个也是可以的
不太行的场景
- Safari 浏览器
为什么 v0.4.2 比 v0.0.2 强在传播
| v0.0.2 | v0.4.2 | |
|---|---|---|
| 水印字符 | chr(0x7F) DEL | U+2060 / U+FEFF 零宽字符 |
| 是否可见 | 终端中显示为乱码 | 完全不可见 |
| 复制粘贴 | 大概率丢失 | 多数平台保留 |
| 适用场景 | 本地文件隐写 | 跨平台传播溯源 |
v0.4.2 的设计目标就是让水印跟着文字走——复制到微信、钉钉、知乎,水印都在。这才是实际生产环境该用的版本。
九、抗篡改能力分析
作者说"经过一定范围的修改仍能提取”,实际上没那么强。具体看怎么改、改哪里。
v0.0.2 的抗篡改能力(基本没有)
水印是逐字符插在载体文本里的,每个 bit 对应一个载体字符位置。任何改变字符数量的操作都会导致错位:
| 篡改类型 | 能否提取 | 原因 |
|---|---|---|
| 末尾增删文字 | ✅ | 水印在前面,不影响 |
| 开头增删文字 | ❌ | 所有 bit 位置错位 |
| 中间增删字符 | ❌ | 该位置之后全部错位 |
| 改字符内容但不增删 | ✅ | bit 跟位置走,内容变了不影响 |
| 复制粘贴丢了个空格 | ❌ | 少一个字符就错位 |
结论:v0.0.2 只能抗"末尾加东西",其他改动基本一改就废。
v0.4.2 的抗篡改能力(有限但更强)
v0.4.2 把水印作为连续的零宽字符块插在文本某个位置。提取时从头扫描,找到零宽字符就开始读,遇到正常文字就停:
1# 提取逻辑简化:
2for char in text:
3 if char 是零宽字符: # 属于水印,记录 bit
4 ...
5 else:
6 break # 遇到正常文字,结束提取
| 篡改类型 | 能否提取 | 原因 |
|---|---|---|
| 水印块之前加文字 | ✅ | 扫描跳过,找到水印就提取 |
| 水印块之后加文字 | ✅ | 遇到正常文字就停,后面不管 |
| 删掉零宽字符 | ❌ | 水印被直接破坏 |
| Unicode 规范化(部分编辑器) | ❌ | 可能删除零宽字符 |

使用vim打开盲水印如图
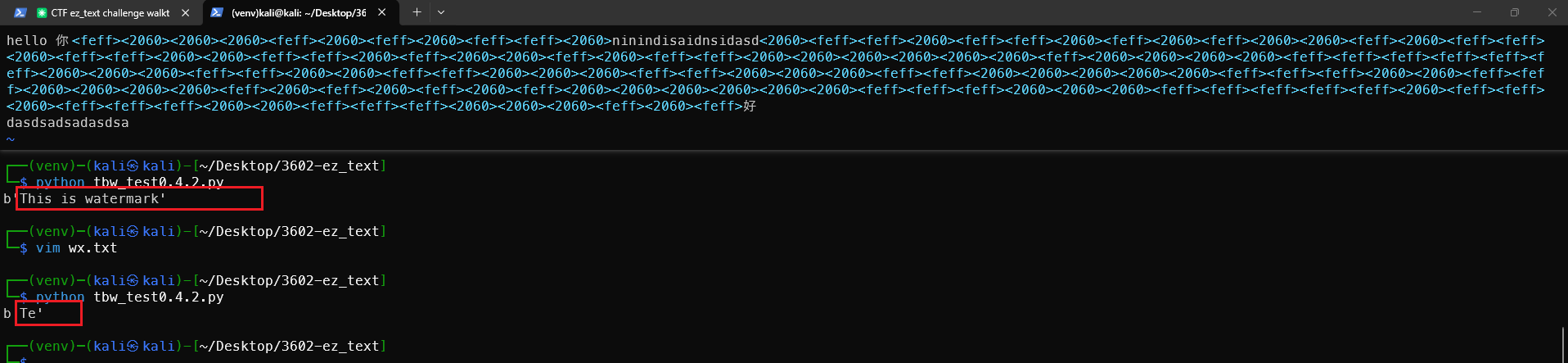
在水印块上面动手脚密文就会被破坏了。用 v0.4.2 对 hello 你好 嵌入水印,vim 中可直接看到水印块:
你好<feff><2060><feff><2060><feff>好
↑------ 水印块 ------↑
| 操作 | 结果 |
|---|---|
| 在末尾加文字 | ✅ 正常解密 |
在水印块中插入任意字符(包括 < > 之间) | ❌ 解密失败 |
原因:提取时顺序扫描零宽字符,遇到任何非零宽字符就认为水印块结束。在 <feff> 和 <2060> 之间插入普通字符,即使不破坏零宽字符本身,也会导致扫描提前终止,后续数据全部丢失。
结论:水印块是连续的零宽字符流,中间不能断。
真正的"抗编辑"需要重复嵌入 + 纠错码
上面两个版本都没做重复嵌入和纠错。如果要抗编辑(改词、删段、翻译),需要:
简单嵌入:
"今[A]天[B]天气真好..."
→ 删两个字水印就没了
重复 + 纠错:
"今[A]天[B]天气真好...适[B]出[CRC]去走走。心[A]情[B]也[CRC]不错。"
→ 删掉一半内容,靠冗余和纠错码仍可恢复
text_blind_watermark 库本身没有实现这个功能。要真正抗篡改,需要在应用层自己加重复嵌入和纠错逻辑。
一句话总结
作者说的"经过一定范围的修改仍能提取",指的是水印区域以外的修改。水印区域内的任何增删改都会导致提取失败。真正生产级的抗篡改需要额外的纠错机制。

