
关注泷羽Sec和泷羽Sec-静安公众号,这里会定期更新与 OSCP、渗透测试等相关的最新文章,帮助你理解网络安全领域的最新动态。后台回复“OSCP配套工具”获取本文的工具
DNS枚举
DNS枚举在主动信息收集(尤其是渗透测试或红队行动初期)中扮演着核心角色,它的核心价值在于揭示目标组织面向互联网的域名基础设施和相关系统的细节,从而勾勒出初步的攻击面。
- 发现子域名:
- 这是最重要的目的之一。主域名(如
example.com)可能只暴露少量服务,但大量内部开发、测试、特定部门或业务线使用的系统往往部署在子域名下(如admin.example.com,dev.example.com,vpn.example.com,api.example.com)。 - 枚举这些子域名能显著扩大已知的攻击面,揭示隐藏的、可能安全性较弱的入口点。
- 这是最重要的目的之一。主域名(如
- 识别关联的主机和服务:
- 通过查询A记录和AAAA记录,DNS枚举能将域名和子域名映射到具体的IPv4和IPv6地址。这直接揭示了目标实际运行网络服务的计算机位置(主机)。
- 知道主机IP是后续扫描(端口扫描、服务识别)和潜在攻击的起点。
- 发现电子邮件服务器:
- 通过查询MX记录,可以确定目标组织用于接收电子邮件的邮件服务器及其优先级。这是针对邮件系统进行渗透测试或发起鱼叉式钓鱼攻击的重要信息。
- 定位关键网络基础设施:
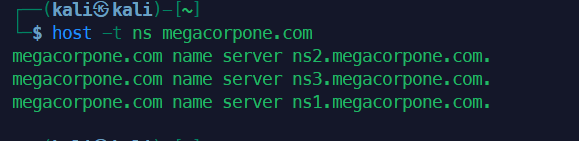
- 名称服务器记录:通过查询NS记录,确定该域名由哪些权威DNS服务器负责解析。攻击这些服务器或其配置弱点可能导致DNS劫持或拒绝服务。
- 邮件服务器信息:MX记录(如上所述)。
- 反向代理/CDN后端源站:有时CNAME记录可能指向CDN提供商的域名(如
assets.example.com CNAME assets.customer-cdn.net),但也可能指向内部的负载均衡器或实际的应用服务器。
- 查找别名和重定向:
- CNAME记录将一个域名或子域名别名到另一个规范的域名。这有助于理解:
- 基础设施架构(例如,某个子域名实际指向另一个服务器上的服务)。
- 是否使用了第三方服务(例如,CNAME到AWS S3桶或第三方CMS)。
- 可能指向内部系统(如果配置错误或暴露)。
- CNAME记录将一个域名或子域名别名到另一个规范的域名。这有助于理解:
- 探测安全配置信息:
- TXT记录:
- SPF记录:用于防止邮件欺骗,包含允许发送该域名邮件的服务器IP地址或主机名列表。这可以直接泄露邮件服务器的IP范围。
- DKIM记录:提供邮件签名公钥,用于验证邮件完整性。
- DMARC记录:指定如何处理不符合SPF/DKIM的邮件的策略。
- 意外信息:有时管理员会在TXT记录中留下注释、内部服务器名称、验证码(用于验证域名所有权,可能被滥用)甚至凭据(严重错误)。
- 暴露的服务器类型/版本:有时SRV记录(指向特定服务的位置,如
_ldap._tcp.example.com)或CNAME可以暗示底层运行的服务器类型(如Windows域控制器)。
- TXT记录:
- 收集组织的网络边界信息:
- 通过获取所有与目标主域名及其子域名相关的A、AAAA记录,实际上是在映射目标组织在公网上拥有和控制的IP地址块。这对于理解他们的整体网络规模、可能的AS编号以及后续的网络层扫描(如端口扫描整个IP段)至关重要。
- 构建目标组织的数字资产清单:
- DNS枚举结果是构建目标组织完整互联网资产清单的基础。它列出了所有已知的、面向互联网的域名和对应的主机/IP地址。
为什么DNS枚举如此重要?
- 非侵入性(相对而言): 标准的DNS查询(非区域传输)通常被认为是良性的、合法的互联网流量,难以被检测为恶意行为。它是一个相对隐蔽的起点。
- 信息价值高: 收集到的信息对于规划后续攻击步骤(下一步扫描哪个IP/端口,攻击哪个子域,如何伪造邮件)具有极高的指导价值。
- 易被忽略的安全点: 许多组织在子域名、废弃域名或DNS记录配置上存在疏忽(如暴露内部服务器名或IP),DNS枚举是发现这些弱点的有效方法。
- 攻击面扩展的核心: 未发现的子域名或IP地址意味着未评估的安全风险。DNS枚举确保在深入了解具体漏洞前,尽可能全面地掌握目标暴露在外的入口点。
DNS记录类型详解
- ns - 包含载域DNS记录得授权服务器的名称
- A- 包含主机名的IP地址
- MX - 包含负责处理该域电子邮件的服务器名称,可以有多个MX记录
- PTR 别名记录(反向区域使用)
- CNAME - 别名记录,指向其他主机记录
- TXT - 文本记录,可包含任意数据,常用于域所有权验证
NS(Name Server) 记录:- 含义: 这是最基础、最关键的记录之一。它指定了哪些 DNS 服务器是某个特定域(比如
example.com)的权威服务器。权威服务器存储着该域所有 DNS 记录的官方、最终版本。 - 作用: 当你的电脑或其他解析器需要查询
example.com或其子域(如www.example.com)的信息时,它首先会查找根 DNS 服务器,然后根据.com的顶级域服务器指引,最终找到example.com的 NS 记录指向的服务器。这些服务器才能提供example.com域下所有记录的准确答案(如 A、MX、CNAME 等)。 - 重要性: 没有正确的 NS 记录,整个域的 DNS 解析就无法正常工作。攻击者常通过 NS 记录来定位目标组织的权威 DNS 服务器,这些服务器本身也可能是攻击目标。
- 示例:
example.com. IN NS ns1.provider.com.example.com. IN NS ns2.provider.com.
- 含义: 这是最基础、最关键的记录之一。它指定了哪些 DNS 服务器是某个特定域(比如
A(Address) 记录:- 含义: 这是最常用的记录类型。它将一个主机名(域名或子域名)直接映射到一个 IPv4 地址。
- 作用: 当你在浏览器输入
www.example.com时,DNS 系统最终会查找该主机名的 A 记录,获得其对应的 IP 地址(如93.184.216.34),然后你的浏览器才能连接到该 IP 地址的服务器获取网页内容。它负责将“人类可读”的名字转换成机器使用的 IP 地址。 - 示例:
www.example.com. IN A 93.184.216.34
AAAA(Quad-A) 记录:- 含义: 功能与 A 记录完全相同,但它映射的是 IPv6 地址。
- 作用: 随着 IPv4 地址耗尽,IPv6 越来越重要。AAAA 记录让主机名能够解析到 IPv6 地址。
- 示例:
www.example.com. IN AAAA 2606:2800:220:1:248:1893:25c8:1946
MX(Mail eXchange) 记录:- 含义: 指定负责接收发送到该域(不是特定主机名)的电子邮件的邮件服务器。
- 特点:
- 指向的是主机名(通常有对应的 A/AAAA 记录),而不是直接指向 IP 地址。
- 可以有多个 MX 记录,每个记录有一个优先级值(数字越小,优先级越高)。发送邮件的服务器会先尝试连接优先级最高的邮件服务器,如果失败,再尝试优先级较低的。
- 作用: 确保发送到
user@example.com的邮件能被正确路由到处理example.com邮件的服务器上。 - 示例:
example.com. IN MX 10 mailserver1.example.com.example.com. IN MX 20 mailserver2.example.com.
PTR(Pointer) 记录:- 含义: 用于反向 DNS 查找。它将一个 IP 地址映射回一个主机名。
- 作用: 与 A/AAAA 记录相反。主要用于:
- 日志记录: 在系统日志中显示 IP 地址对应的主机名,更易读。
- 网络诊断:
traceroute,ping等工具有时会尝试反向解析 IP 地址。 - 安全验证: 一些邮件服务器会检查发送方 IP 的反向解析记录是否与声称的发件域匹配(作为反垃圾邮件措施的一部分,但效果有限)。
- 系统管理: 识别网络上的设备。
- 存储位置: PTR 记录存储在特殊的 DNS 域中,通常是
in-addr.arpa(IPv4) 或ip6.arpa(IPv6)。 - 示例:
34.216.184.93.in-addr.arpa. IN PTR www.example.com.(这是93.184.216.34的反向记录)
CNAME(Canonical Name) 记录:- 含义: 为一个主机名设置一个别名。它指向的是另一个主机名(称为规范名或真实名),而不是直接指向 IP 地址。
- 作用:
- 简化管理: 例如,你可以让
www.example.com作为webserver-prod-lb-01.example.com的别名。如果真实服务器的 IP 地址变了,你只需要更新webserver-prod-lb-01.example.com的 A 记录,所有指向它的 CNAME 会自动生效。 - 指向外部服务: 例如,
files.example.com的 CNAME 可能指向某个云存储服务商提供的域名(如example.bucket.s3.amazonaws.com)。
- 简化管理: 例如,你可以让
- 重要规则:
- CNAME 记录不能与其他记录类型(如 MX, TXT, NS)共存于同一个主机名下。例如,
example.com不能同时有 CNAME 记录和 MX 记录。 - CNAME 应该指向一个有效的、最终会解析到 A 或 AAAA 记录的主机名。
- CNAME 记录不能与其他记录类型(如 MX, TXT, NS)共存于同一个主机名下。例如,
- 示例:
www.example.com. IN CNAME webserver-prod-lb-01.example.com.
TXT(Text) 记录:- 含义: 允许域管理员在 DNS 中存储任意文本信息。
- 用途广泛:
- SPF (Sender Policy Framework): 指定哪些邮件服务器被授权代表该域发送邮件(格式如
v=spf1 include:_spf.google.com ~all)。用于反垃圾邮件。 - DKIM (DomainKeys Identified Mail): 存储用于验证邮件签名的公钥(格式如
v=DKIM1; k=rsa; p=MIGfMA0GCSqGSIb3DQEBAQUAA4GNADCBiQKBgQC...)。 - DMARC (Domain-based Message Authentication, Reporting & Conformance): 定义如何处理未通过 SPF 或 DKIM 检查的邮件,以及发送报告的位置(格式如
v=DMARC1; p=reject; rua=mailto:dmarc-reports@example.com)。 - 域所有权验证: 许多在线服务(如 Google Workspace, SSL 证书颁发机构)会让你在域名的 TXT 记录中添加一段特定文本(如
google-site-verification=abcdefg123456)来证明你拥有该域。 - 其他信息: 有时会包含联系人信息、策略声明或其他任意备注(但应避免存储敏感信息)。
- SPF (Sender Policy Framework): 指定哪些邮件服务器被授权代表该域发送邮件(格式如
- 示例:
example.com. IN TXT "v=spf1 include:_spf.google.com ~all"_dmarc.example.com. IN TXT "v=DMARC1; p=none; rua=mailto:dmarc-reports@example.com"
其他重要的 DNS 记录类型:
SOA(Start of Authority) 记录:- 含义: 每个 DNS 区域文件必须包含且只能包含一个 SOA 记录。它包含关于该 DNS 区域的管理信息。
- 包含内容: 主要名称服务器 (MNAME)、区域负责人的邮箱 (RNAME - 注意格式,如
admin.example.com实际是admin.example.com,第一个点通常写作admin\.example.com)、区域序列号 (SERIAL - 每次修改区域文件需递增此号)、刷新间隔 (REFRESH)、重试间隔 (RETRY)、过期时间 (EXPIRE)、负缓存 TTL (MINIMUM)。 - 作用: 用于区域传输(从主服务器同步到从服务器)和缓存管理。序列号是判断区域文件是否更新的关键。
SRV(Service) 记录:含义: 指定提供特定服务(如 LDAP, SIP, XMPP)的服务器的主机名和端口号。
格式:
_Service._Proto.Name TTL Class SRV Priority Weight Port Target_Service:服务名称(如_ldap,_sip)。_Proto:协议(通常是_tcp或_udp)。Name:该记录所适用的域名。Priority:类似 MX 记录的优先级。Weight:在相同优先级下用于负载均衡的权重。Port:服务运行的端口号。Target:提供该服务的主机名(需有 A/AAAA 记录)。
作用: 使客户端能够自动发现特定服务的服务器位置(哪个主机、哪个端口)。
示例:
_sip._tcp.example.com. IN SRV 10 60 5060 sipserver.example.com.
在 Kali Linux 中查询 DNS 记录的工具
Kali Linux 自带了许多强大的网络工具,查询 DNS 记录主要使用 dig 和 nslookup,有时也会用到 host。
dig(Domain Information Groper):最强大、最灵活、最推荐的工具。 提供详细输出,非常适合调试和理解 DNS 响应。
基本语法:
dig [@server] [domain] [record_type]@server:可选,指定查询哪个 DNS 服务器(如@8.8.8.8)。不指定则使用系统默认 DNS。domain:要查询的域名或主机名。record_type:要查询的记录类型(如A,AAAA,MX,NS,TXT,CNAME,SOA,PTR,SRV)。不指定默认为A。
常用选项:
+short:只显示最精简的结果(通常就是记录值)。+noall +answer:只显示查询的答案部分(最常用)。
查询示例:
查询
example.com的 A 记录:dig example.com A或dig +short example.com A查询
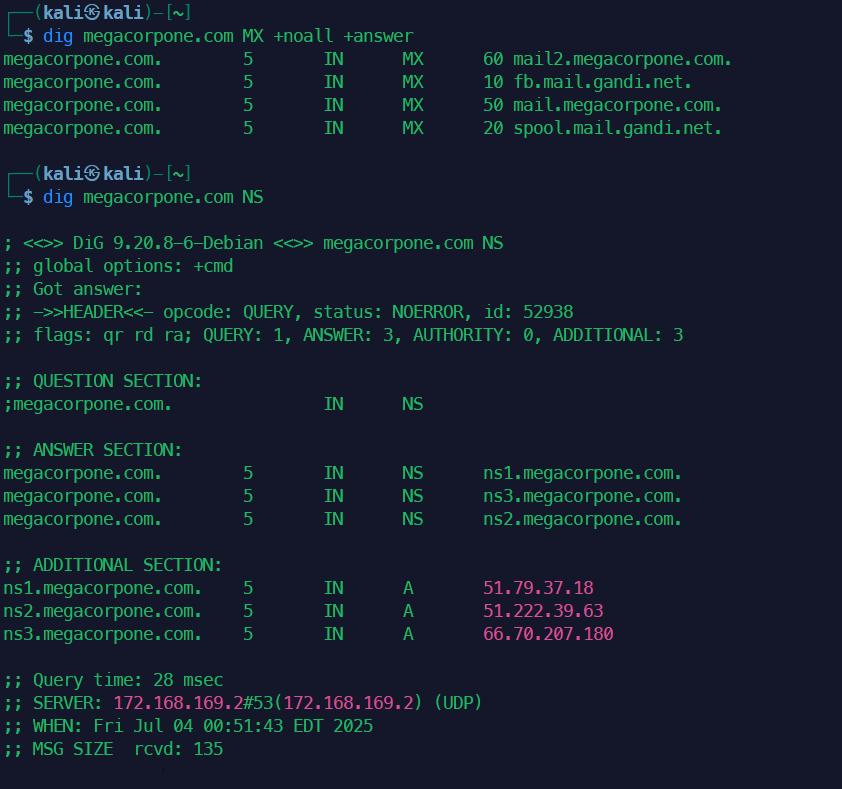
example.com的 MX 记录:dig example.com MX +noall +answer查询
example.com的 NS 记录:dig example.com NS查询
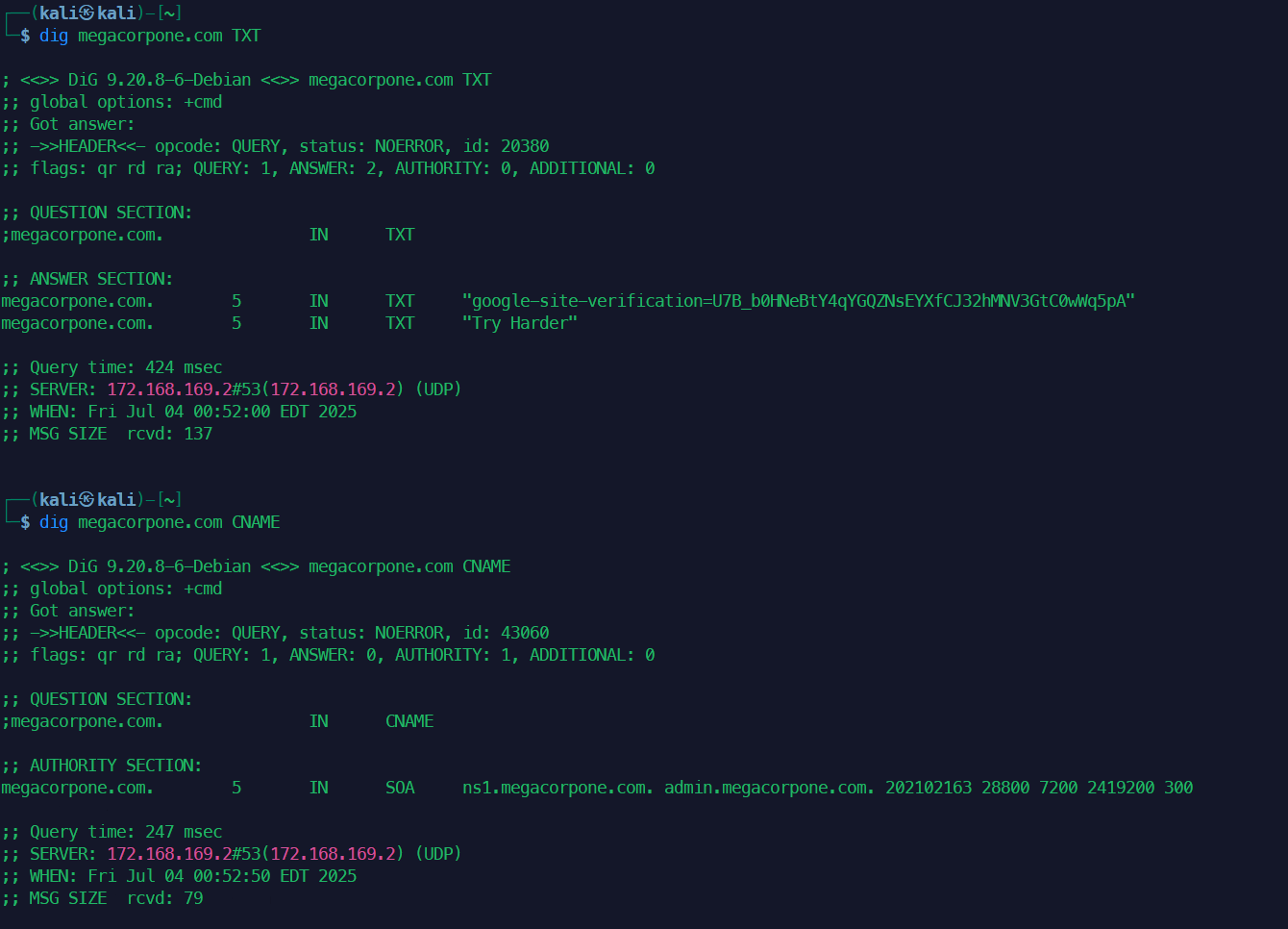
example.com的 TXT 记录(常用于看 SPF/DKIM/DMARC):dig example.com TXT查询
www.example.com的 CNAME 记录:dig www.example.com CNAME查询
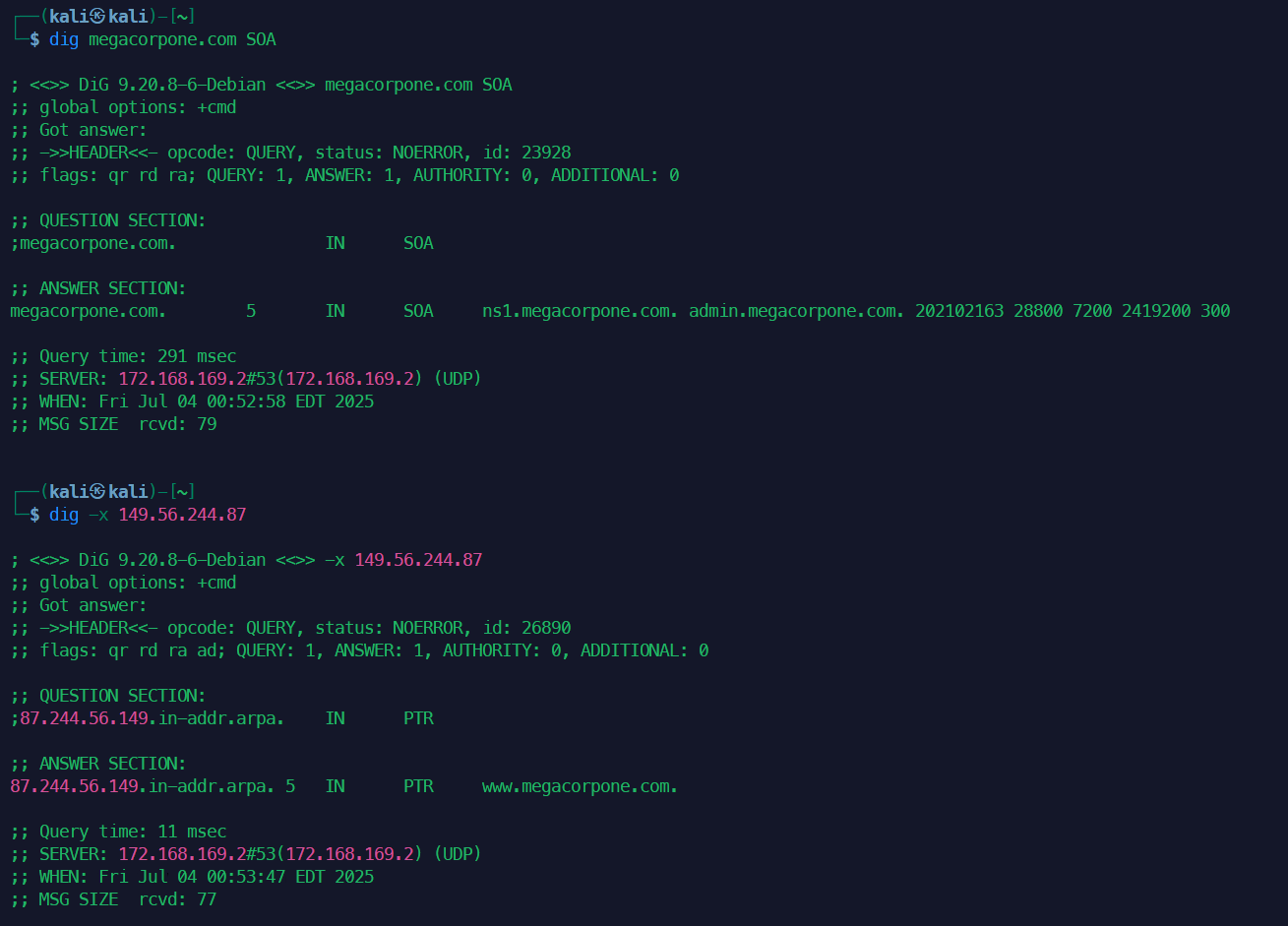
example.com的 SOA 记录:dig example.com SOA查询 PTR 记录(反向解析
93.184.216.34):dig -x 93.184.216.34查询 SRV 记录(如 SIP TCP 服务):
dig _sip._tcp.example.com SRV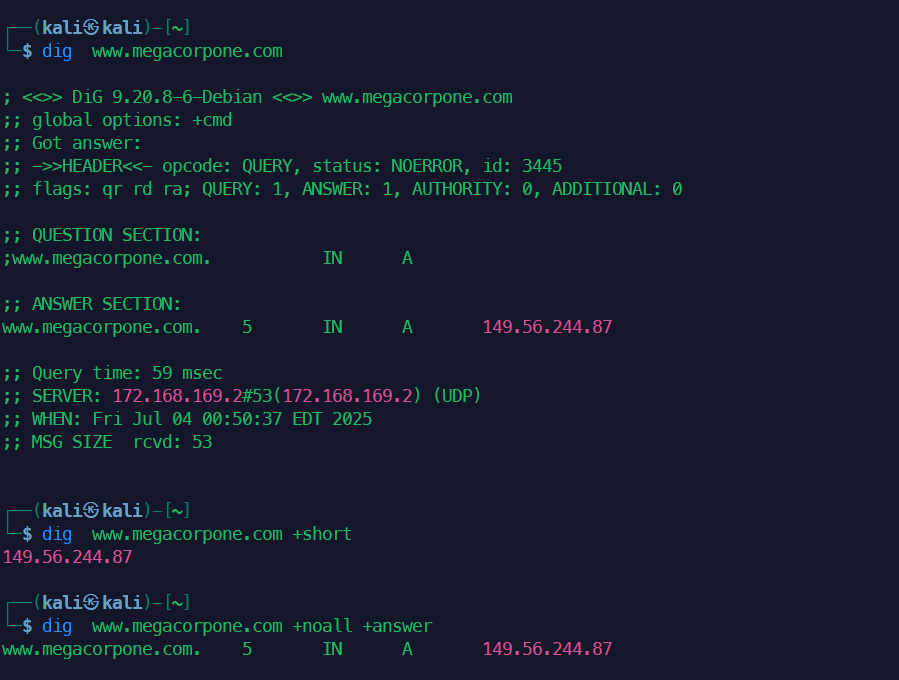
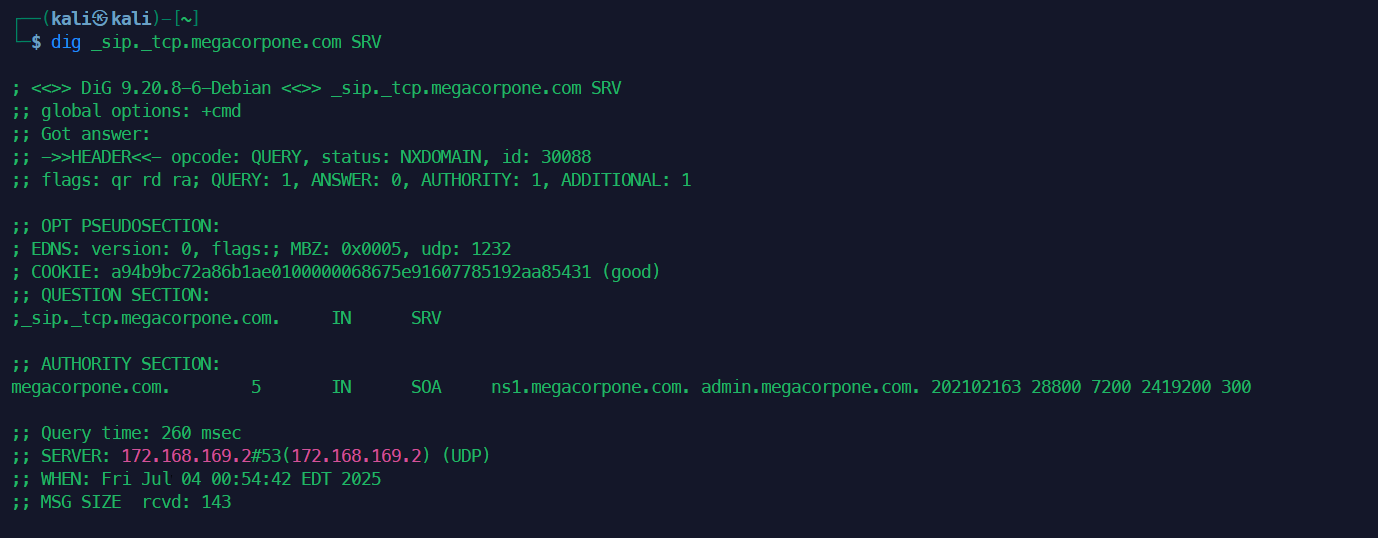
nslookup:交互式命令行工具, 也支持非交互模式。功能不如
dig强大,但更简单直观。基本语法(非交互):
nslookup [-type=record_type] [domain] [server]-type=record_type:指定记录类型(如a,aaaa,mx,ns,txt,cname,soa,ptr)。domain:要查询的域名或主机名。server:可选,指定查询哪个 DNS 服务器。
交互模式: 直接输入
nslookup,然后按提示输入命令:
server 8.8.8.8:设置默认查询服务器。set type=mx:设置查询的记录类型。example.com:执行查询。exit:退出。
查询示例:
查询
example.com的 A 记录:nslookup example.com查询
example.com的 MX 记录:nslookup -type=mx example.com查询
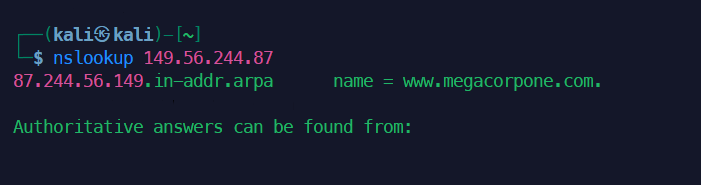
example.com的 TXT 记录:nslookup -type=txt example.com查询 PTR 记录:
nslookup 93.184.216.34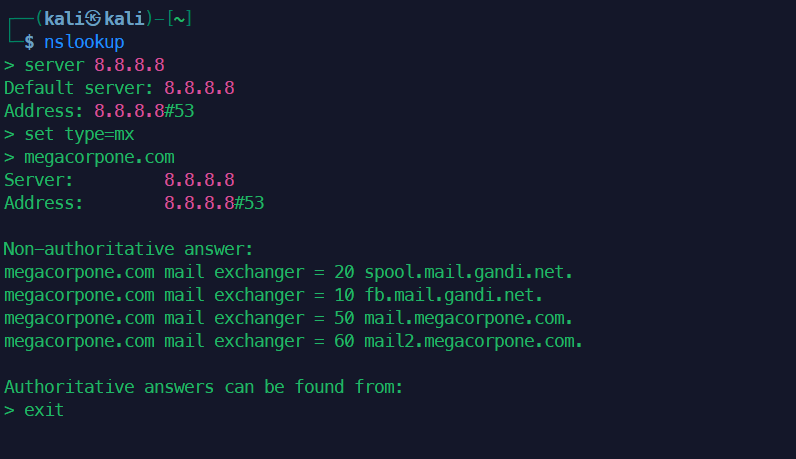
host:简单易用的工具, 输出比
dig +short稍详细一点,但不如dig完整。基本语法:
host [-t record_type] [domain] [server] └─$ host -v Usage: host [-aCdilrTvVw] [-c class] [-N ndots] [-t type] [-W time] [-R number] [-m flag] [-p port] hostname [server] -a is equivalent to -v -t ANY -A is like -a but omits RRSIG, NSEC, NSEC3 -c specifies query class for non-IN data -C compares SOA records on authoritative nameservers -d is equivalent to -v -l lists all hosts in a domain, using AXFR -m set memory debugging flag (trace|record|usage) -N changes the number of dots allowed before root lookup is done -p specifies the port on the server to query -r disables recursive processing -R specifies number of retries for UDP packets -s a SERVFAIL response should stop query -t specifies the query type -T enables TCP/IP mode -U enables UDP mode -v enables verbose output -V print version number and exit -w specifies to wait forever for a reply -W specifies how long to wait for a reply -4 use IPv4 query transport only -6 use IPv6 query transport only 用法:host [-aCdilrTvVw][-c 类别][-N 点数][-t 类型][-W 时间] [-R 次数][-m 标志][-p 端口]主机名 [服务器] -a 等同于 -v -t ANY -A 类似 -a 但不包含 RRSIG、NSEC、NSEC3 -c 指定非 IN 数据的查询类别 -C 比较权威名称服务器上的 SOA 记录 -d 等同于 -v -l 列出域中的所有主机,使用 AXFR -m 设置内存调试标志(跟踪记录|使用情况) N 更改在执行根查找前允许的点数 -p 指定要查询的服务器端口 -r 禁用递归处理 -R 指定 UDP 数据包的重试次数 -s SERVFAIL 响应应停止查询 -t 指定查询类型 -T 启用 TCP/IP 模式 -U 启用 UDP 模式 -v 启用详细输出 -V 打印版本号并退出 -w 指定无限期等待回复 -W 指定等待回复的时间 -4 仅使用 IPv4 查询传输 -6 仅使用 IPv6 查询传输-t record_type:指定记录类型(如a,aaaa,mx,ns,txt,cname,soa,ptr)。domain:要查询的域名或主机名。server:可选,指定查询哪个 DNS 服务器。
查询示例:
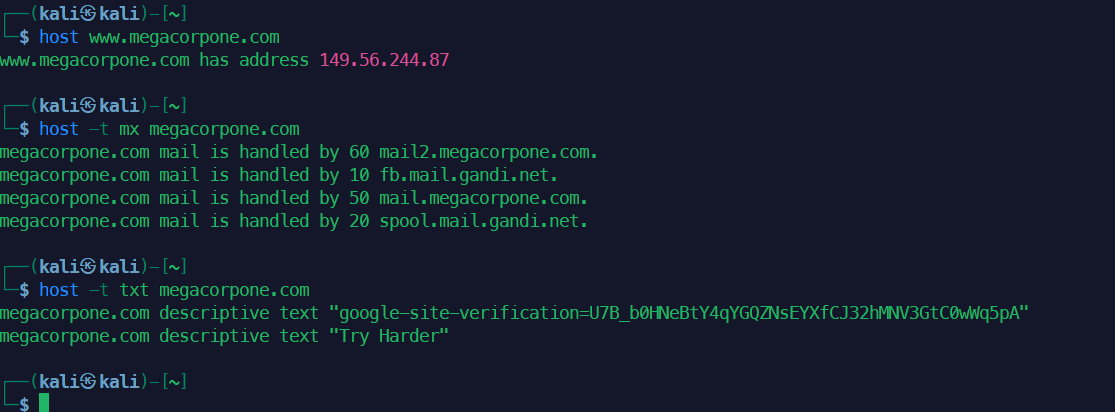
- 查询
example.com的 A 记录:host example.com - 查询
example.com的 MX 记录:host -t mx example.com - 查询
example.com的 TXT 记录:host -t txt example.com - 查询 PTR 记录:
host 93.184.216.34
- 查询
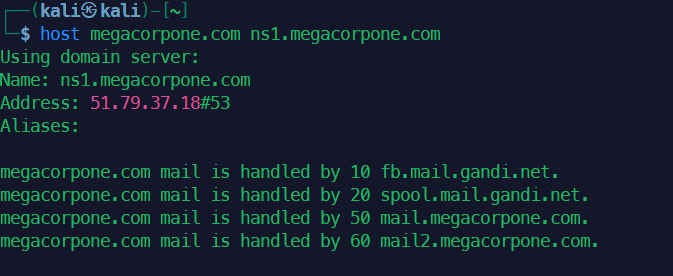
1host www.megacorpone.com
2host -t mx megacorpone.com
3host -t txt megacorpone.com
4host -t ns megacorpone.com
5host -C megacorpone.com # 比较所有权威DNS服务器的 SOA 序列号

反查IP对应的域名


总结:
dig是专业首选,信息最全,功能最强。nslookup交互模式适合简单探索。host适合快速获取简洁结果。
当然,DNS查询也可以通过一些在线网站查询。
正向子域名爆破
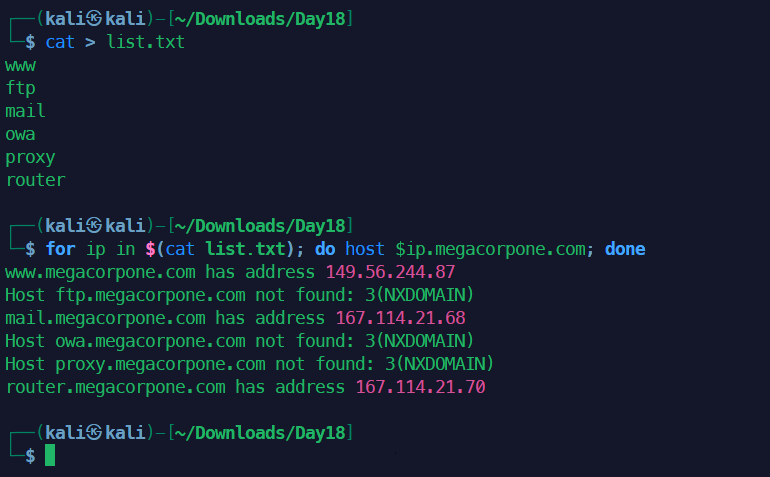
写一个列表,用循环来实现爆破
1cat > list.txt
2www
3ftp
4mail
5owa
6proxy
7router
8# 回车后按ctrl D 结束保存
9for ip in $(cat list.txt); do host $ip.megacorpone.com; done
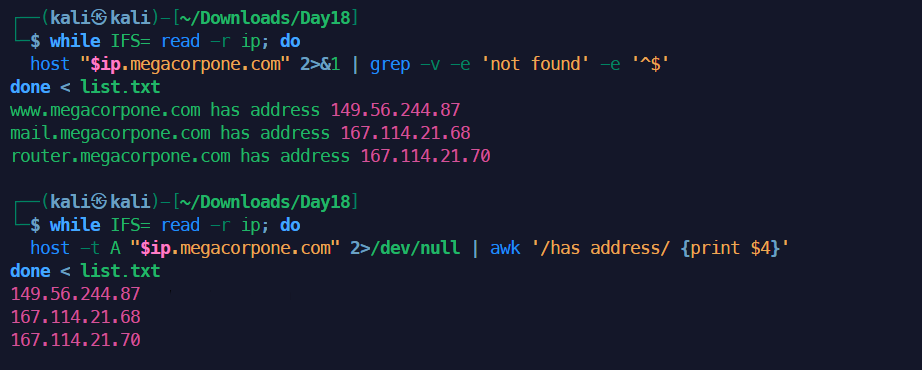
使用AI帮助我们改进一下这个命令就是:
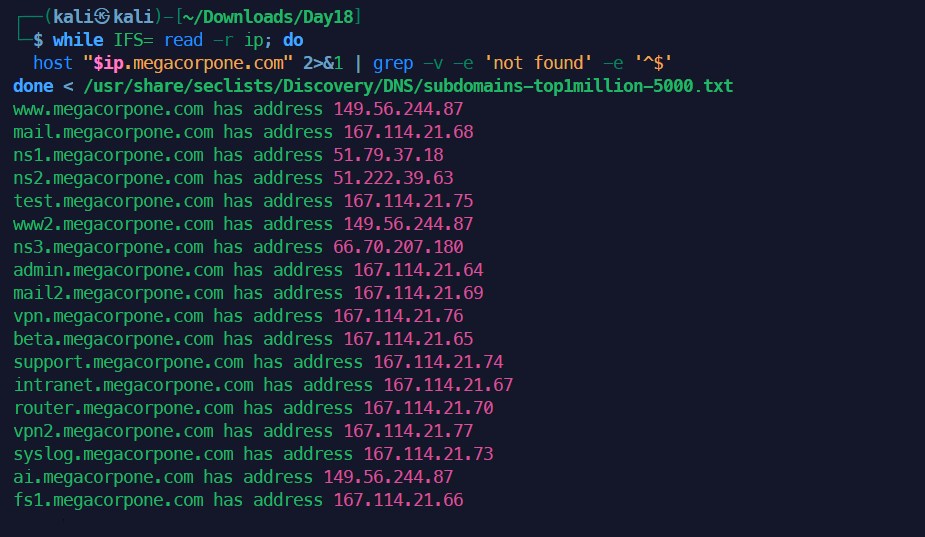
1while IFS= read -r subdomain; do
2 host "$subdomain.megacorpone.com" 2>&1 | grep -v -e 'not found' -e '^$'
3done < list.txt
如果只想要IP就是
1while IFS= read -r subdomain; do
2 host -t A "$subdomain.megacorpone.com" 2>/dev/null | awk '/has address/ {print $4}'
3done < list.txt
想要更全的子域名大字典可以用
1sudo apt install seclists
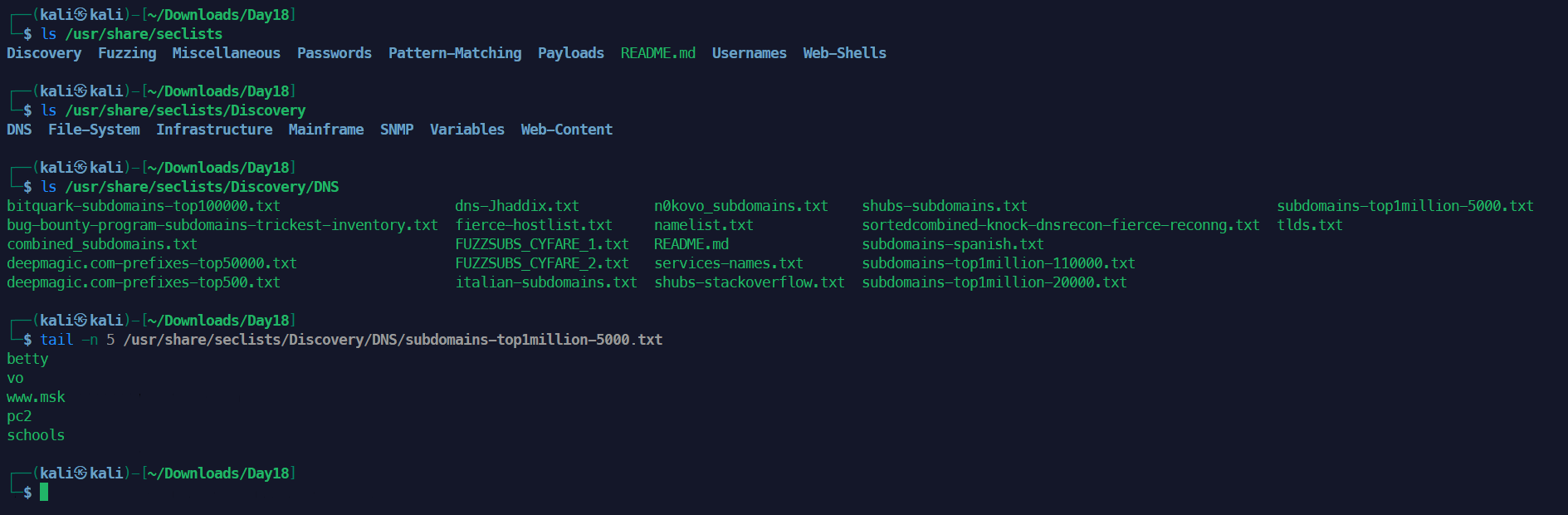
安装后在 /usr/share/seclists目录下找到更多子域名列表来爆破,在Github上也能找到更多更强大的字典来爆破,日常渗透过程中也可以注意收集目标常用的信息来自制字典。
字典越强大,扫的东西越多。
Similar Projects
- Assetnote Wordlists: High quality wordlists for content and subdomain discovery which are automatically updated every month.
- fuzz.txt: Wordlists of “potentially dangerous” files.
- FuzzDB: Dictionary of attack patterns and primitives for black-box application fault injection and resource discovery.
- PayloadsAllTheThings: A list of useful payloads and bypass for Web Application Security and Pentest/CTF
- BiblePass: Wordlists compiled from Bible verses
- SamLists: Data-driven wordlists containing HTTP parameter names, directory names and filenames.
Wordlist Tools
- Cook: A wordlist framework. An overpowered wordlist generator, splitter, merger, finder and saver. Cook facilitates the creation of permutations and combinations with a variety of encodings and many more features.
- Wl: CLI utility for converting strings to a given casing style.
- CeWL: Custom Word List generator.
用AI帮我们把工具加强一下。
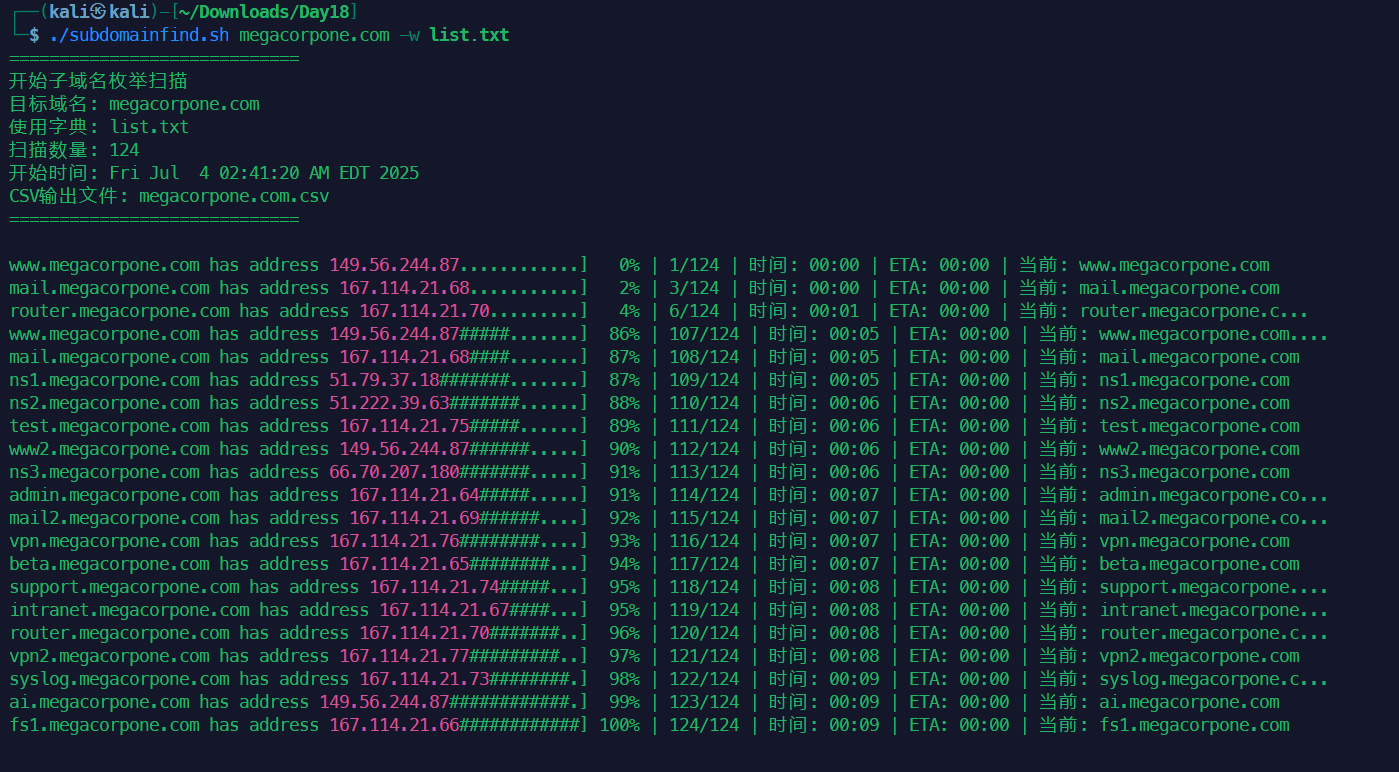
1#!/bin/bash
2
3# 脚本名称: subdomainfind.sh
4# 功能: 子域名枚举工具,支持原始输出、格式化表格和CSV导出
5# 用法: ./subdomainfind.sh 域名 [-w 字典文件] [-o 输出文件]
6
7# 错误处理函数
8die() {
9 echo "错误: $1" >&2
10 echo "用法: $0 域名 [-w 字典文件] [-o 输出文件]"
11 exit 1
12}
13
14# 检查参数
15if [ $# -eq 0 ]; then
16 die "缺少域名参数"
17fi
18
19DOMAIN="$1"
20DEFAULT_WORDLIST="/usr/share/seclists/Discovery/DNS/subdomains-top1million-5000.txt"
21WORDLIST=""
22OUTPUT_FILE=""
23CSV_OUTPUT=""
24
25# 处理参数
26shift
27while [ $# -gt 0 ]; do
28 case "$1" in
29 -w)
30 shift
31 WORDLIST="$1"
32 if [ -z "$WORDLIST" ]; then
33 die "-w 需要指定字典文件"
34 fi
35 if [ ! -f "$WORDLIST" ]; then
36 die "字典文件不存在: $WORDLIST"
37 fi
38 ;;
39 -o)
40 shift
41 OUTPUT_FILE="$1"
42 if [ -z "$OUTPUT_FILE" ]; then
43 die "-o 需要指定输出文件名"
44 fi
45 CSV_OUTPUT="${OUTPUT_FILE%.csv}.csv"
46 ;;
47 *)
48 die "未知参数: $1"
49 ;;
50 esac
51 shift
52done
53
54# 设置默认字典
55if [ -z "$WORDLIST" ]; then
56 WORDLIST="$DEFAULT_WORDLIST"
57 if [ ! -f "$DEFAULT_WORDLIST" ]; then
58 die "默认字典不存在: $DEFAULT_WORDLIST"
59 fi
60 echo "使用默认字典: $WORDLIST"
61fi
62
63# 设置默认输出文件
64if [ -z "$CSV_OUTPUT" ]; then
65 SAFE_DOMAIN=$(echo "$DOMAIN" | tr -cd '[:alnum:]._-')
66 CSV_OUTPUT="${SAFE_DOMAIN}.csv"
67fi
68
69# 创建临时文件存储结果
70RESULT_FILE=$(mktemp)
71
72# 获取字典行数
73TOTAL=$(wc -l < "$WORDLIST" 2>/dev/null || die "无法读取字典文件")
74
75# 开始扫描
76echo "============================="
77echo "开始子域名枚举扫描"
78echo "目标域名: $DOMAIN"
79echo "使用字典: $WORDLIST"
80echo "扫描数量: $TOTAL"
81echo "开始时间: $(date)"
82echo "CSV输出文件: $CSV_OUTPUT"
83echo "============================="
84echo
85
86START_TIME=$(date +%s)
87COUNT=0
88FOUND=0
89
90# 初始化CSV文件
91echo "子域名,IP地址" > "$CSV_OUTPUT"
92
93# 主扫描循环
94while IFS= read -r subdomain; do
95 # 进度统计
96 ((COUNT++))
97
98 # 计算时间和进度
99 CURRENT_TIME=$(date +%s)
100 ELAPSED_SEC=$((CURRENT_TIME - START_TIME))
101 if [ $COUNT -gt 0 ]; then
102 AVG_TIME_PER_REC=$((ELAPSED_SEC / COUNT))
103 REMAINING=$((TOTAL - COUNT))
104 ESTIMATED_REMAINING_SEC=$((AVG_TIME_PER_REC * REMAINING))
105 MINS_REMAINING=$((ESTIMATED_REMAINING_SEC / 60))
106 SECS_REMAINING=$((ESTIMATED_REMAINING_SEC % 60))
107 fi
108
109 # 计算进度百分比
110 PERCENT=$((COUNT * 100 / TOTAL))
111
112 # 创建简洁的当前查询显示 (最多显示前20个字符)
113 current_query="${subdomain}.$DOMAIN"
114 display_query="${current_query:0:20}"
115 if [ ${#current_query} -gt 20 ]; then
116 display_query="${display_query}..."
117 fi
118
119 # 创建进度条
120 bar=""
121 for ((i=0; i<50; i++)); do
122 if [ $i -lt $((PERCENT / 2)) ]; then
123 bar="${bar}#"
124 else
125 bar="${bar}."
126 fi
127 done
128
129 # 显示进度信息
130 printf "进度: [%-50s] %3d%% | %d/%d | 时间: %02d:%02d | ETA: %02d:%02d | 当前: %s\r" \
131 "$bar" $PERCENT $COUNT $TOTAL \
132 $((ELAPSED_SEC / 60)) $((ELAPSED_SEC % 60)) \
133 $MINS_REMAINING $SECS_REMAINING \
134 "$display_query"
135
136 # 执行DNS查询
137 result=$(host -t A "${subdomain}.$DOMAIN" 2>/dev/null)
138
139 # 处理结果
140 if [[ "$result" == *"has address"* ]]; then
141 ((FOUND++))
142
143 # 1. 输出原始格式结果
144 echo "$result"
145
146 # 2. 保存结果用于表格
147 echo "$result" | grep -oE '[^ ]+ has address [0-9.]+' >> "$RESULT_FILE"
148
149 # 3. 添加到CSV文件
150 echo "$result" | awk '/has address/ {print $1 "," $4}' >> "$CSV_OUTPUT"
151 fi
152
153done < "$WORDLIST"
154
155# 清除进度行
156printf "\n\n"
157
158# 计算总耗时
159END_TIME=$(date +%s)
160TOTAL_TIME=$((END_TIME - START_TIME))
161
162# 显示表格总结
163if [ -s "$RESULT_FILE" ]; then
164 echo "============================="
165 echo "扫描结果汇总 (活动子域名)"
166 echo "============================="
167 echo
168
169 # 确保表格对齐(包含标题长度)
170 max_sub_len=9 # "Subdomain" 标题长度
171 max_ip_len=10 # "IP Address" 标题长度
172
173 # 读取结果计算最大长度
174 while IFS= read -r line; do
175 subdomain=$(echo "$line" | awk '{print $1}')
176 ip=$(echo "$line" | awk '{print $4}')
177
178 # 处理超长字段
179 subdomain=${subdomain:0:60}
180 ip=${ip:0:15}
181
182 if [ ${#subdomain} -gt $max_sub_len ]; then
183 max_sub_len=${#subdomain}
184 fi
185
186 if [ ${#ip} -gt $max_ip_len ]; then
187 max_ip_len=${#ip}
188 fi
189 done < "$RESULT_FILE"
190
191 # 添加边距
192 max_sub_len=$((max_sub_len + 2))
193 max_ip_len=$((max_ip_len + 2))
194 if [ $max_sub_len -lt 20 ]; then max_sub_len=20; fi
195 if [ $max_ip_len -lt 15 ]; then max_ip_len=15; fi
196
197 # 创建表格顶部
198 printf "┌─%s─┬─%s─┐\n" "$(printf '%*s' "$max_sub_len" "" | tr ' ' '-')" \
199 "$(printf '%*s' "$max_ip_len" "" | tr ' ' '-')"
200
201 # 表格标题
202 printf "│ %-${max_sub_len}s │ %-${max_ip_len}s │\n" "Subdomain" "IP Address"
203 printf "├─%s─┼─%s─┤\n" "$(printf '%*s' "$max_sub_len" "" | tr ' ' '-')" \
204 "$(printf '%*s' "$max_ip_len" "" | tr ' ' '-')"
205
206 # 表格内容
207 while IFS= read -r line; do
208 subdomain=$(echo "$line" | awk '{print $1}')
209 ip=$(echo "$line" | awk '{print $4}')
210
211 # 截断超长字段
212 subdomain=${subdomain:0:60}
213 ip=${ip:0:15}
214
215 printf "│ %-${max_sub_len}s │ %-${max_ip_len}s │\n" "$subdomain" "$ip"
216 done < "$RESULT_FILE"
217
218 # 表格底部
219 printf "└─%s─┴─%s─┘\n" "$(printf '%*s' "$max_sub_len" "" | tr ' ' '-')" \
220 "$(printf '%*s' "$max_ip_len" "" | tr ' ' '-')"
221 echo
222fi
223
224# 保存原始输出
225if [ -s "$RESULT_FILE" ]; then
226 LOG_FILE="${CSV_OUTPUT%.csv}.log"
227 cp "$RESULT_FILE" "$LOG_FILE"
228else
229 LOG_FILE=""
230fi
231
232# 输出统计信息
233echo "============================="
234echo "扫描完成"
235echo "结束时间: $(date)"
236echo "总耗时: $((TOTAL_TIME / 60)) 分钟 $((TOTAL_TIME % 60)) 秒"
237echo "共扫描: $COUNT 个子域名"
238echo "发现: $FOUND 个活动子域名"
239if [ -n "$LOG_FILE" ]; then
240 echo "原始输出: $LOG_FILE"
241fi
242echo "CSV文件: $CSV_OUTPUT"
243echo "============================="
244
245# 清理临时文件
246rm -f "$RESULT_FILE"
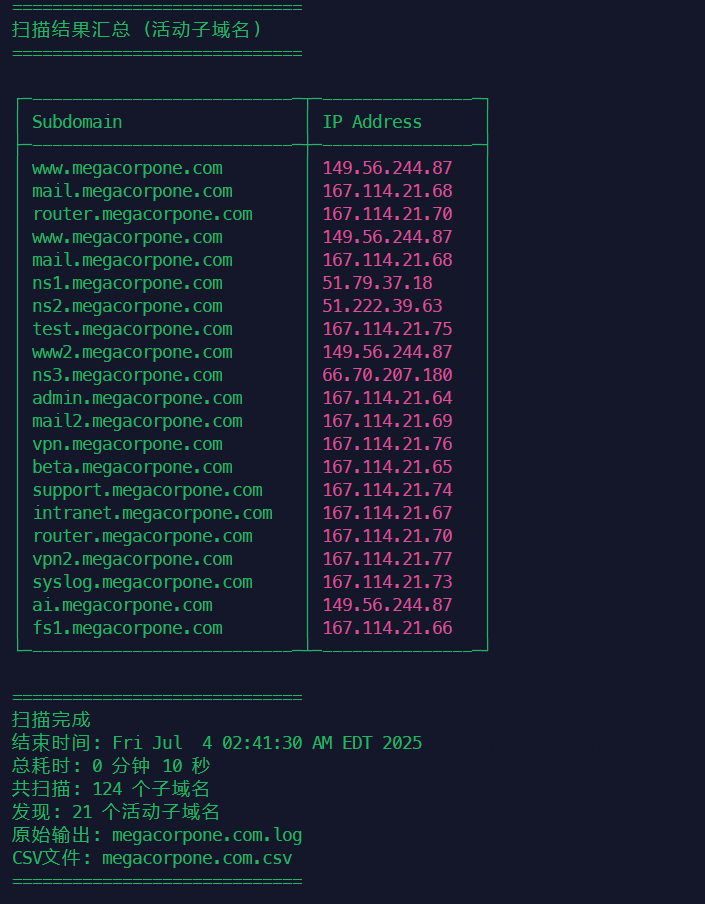
反向C段IP爆破
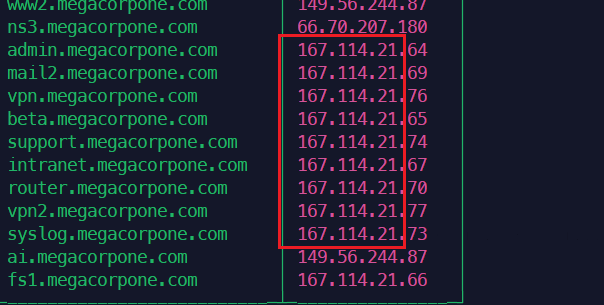
从之前的扫描结果看,这个域名大多数解析到167.114.21.x的C段IP地址,说明这个公司包揽了这个段上的大多数连续的服务器,用来承载业务,那么就有可能存在这个C段中,没有域名,或者说还没来得及挂上域名的测试站点,或者说一个公司某个部门、总部、第三方委托的服务器商之类的角色管理这些服务器,而megacorpone.com这个域名只是他们子公司域名之一,可能还存在其他域名,只要是存在业务关系的,他们的服务器之间一定会存在业务关联,这时候就需要IP反向搜索爆破新域名。
1for Cip in $(seq 50 100); do host 167.114.21.$Cip; done | grep -v "not fou
2nd"
3for Cip in $(seq 0 254); do host 167.114.21.$Cip; done | grep -v "not fou
4nd"
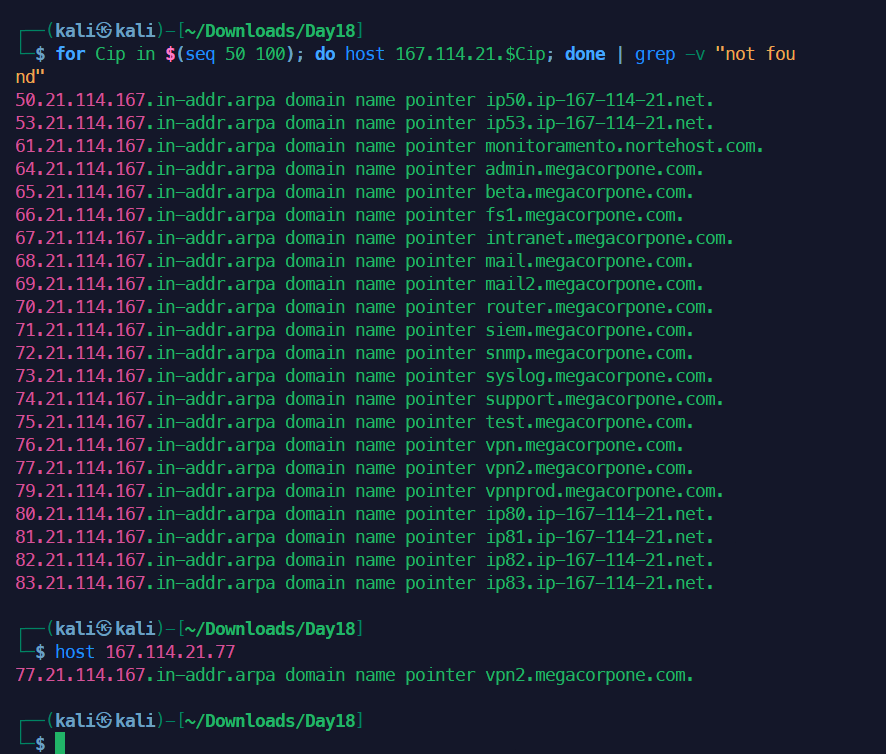
同样的,我们用AI写一个小工具
1#!/bin/bash
2
3# 脚本名称: reverse_dns_scan.sh
4# 功能: 反向DNS扫描工具,支持进度显示、格式化表格和CSV导出
5# 用法: ./reverse_dns_scan.sh 网络地址 起始IP 结束IP
6
7# 错误处理函数
8die() {
9 echo "错误: $1" >&2
10 echo "用法: $0 网络地址 起始IP 结束IP"
11 exit 1
12}
13
14# 检查参数
15if [ $# -ne 3 ]; then
16 die "需要三个参数:网络地址、起始IP和结束IP"
17fi
18
19NETWORK="$1"
20START_IP="$2"
21END_IP="$3"
22
23# 验证IP范围
24if ! [[ "$START_IP" =~ ^[0-9]+$ ]] || ! [[ "$END_IP" =~ ^[0-9]+$ ]]; then
25 die "起始IP和结束IP必须是数字"
26fi
27
28if [ "$START_IP" -gt "$END_IP" ]; then
29 die "起始IP不能大于结束IP"
30fi
31
32# 设置输出文件
33SAFE_NETWORK=$(echo "$NETWORK" | tr -cd '[:alnum:]._-')
34CSV_OUTPUT="${SAFE_NETWORK}_${START_IP}-${END_IP}_reverse_dns.csv"
35
36# 创建临时文件存储结果
37RESULT_FILE=$(mktemp)
38
39# 计算总数
40TOTAL=$((END_IP - START_IP + 1))
41
42# 开始扫描
43echo "============================="
44echo "开始反向DNS扫描"
45echo "网络地址: $NETWORK"
46echo "IP范围: $START_IP - $END_IP"
47echo "扫描数量: $TOTAL"
48echo "开始时间: $(date)"
49echo "CSV输出文件: $CSV_OUTPUT"
50echo "============================="
51echo
52
53START_TIME=$(date +%s)
54COUNT=0
55FOUND=0
56
57# 初始化CSV文件
58echo "IP地址,域名" > "$CSV_OUTPUT"
59
60# 主扫描循环
61for CIP in $(seq "$START_IP" "$END_IP"); do
62 IP="${NETWORK}.${CIP}"
63
64 # 进度统计
65 ((COUNT++))
66
67 # 计算时间和进度
68 CURRENT_TIME=$(date +%s)
69 ELAPSED_SEC=$((CURRENT_TIME - START_TIME))
70 if [ $COUNT -gt 0 ]; then
71 AVG_TIME_PER_REC=$((ELAPSED_SEC / COUNT))
72 REMAINING=$((TOTAL - COUNT))
73 ESTIMATED_REMAINING_SEC=$((AVG_TIME_PER_REC * REMAINING))
74 MINS_REMAINING=$((ESTIMATED_REMAINING_SEC / 60))
75 SECS_REMAINING=$((ESTIMATED_REMAINING_SEC % 60))
76 fi
77
78 # 计算进度百分比
79 PERCENT=$((COUNT * 100 / TOTAL))
80
81 # 创建简洁的当前查询显示
82 display_query="$IP"
83 if [ ${#IP} -gt 25 ]; then
84 display_query="${IP:0:22}..."
85 fi
86
87 # 创建进度条
88 bar=""
89 for ((i=0; i<50; i++)); do
90 if [ $i -lt $((PERCENT / 2)) ]; then
91 bar="${bar}#"
92 else
93 bar="${bar}."
94 fi
95 done
96
97 # 显示进度信息
98 printf "进度: [%-50s] %3d%% | %d/%d | 时间: %02d:%02d | ETA: %02d:%02d | 当前: %s\r" \
99 "$bar" $PERCENT $COUNT $TOTAL \
100 $((ELAPSED_SEC / 60)) $((ELAPSED_SEC % 60)) \
101 $MINS_REMAINING $SECS_REMAINING \
102 "$display_query"
103
104 # 执行反向DNS查询
105 result=$(host "$IP" 2>/dev/null)
106
107 # 处理结果
108 if [[ "$result" == *"domain name pointer"* ]]; then
109 ((FOUND++))
110
111 # 提取域名
112 domain=$(echo "$result" | grep -oP 'domain name pointer \K[^.]+(\.[^.]+)+' | head -1)
113
114 # 1. 输出原始格式结果
115 echo "$result"
116
117 # 2. 保存结果用于表格
118 echo "$IP,$domain" >> "$RESULT_FILE"
119
120 # 3. 添加到CSV文件
121 echo "$IP,$domain" >> "$CSV_OUTPUT"
122 fi
123done
124
125# 清除进度行
126printf "\n\n"
127
128# 计算总耗时
129END_TIME=$(date +%s)
130TOTAL_TIME=$((END_TIME - START_TIME))
131
132# 显示表格总结
133if [ -s "$RESULT_FILE" ]; then
134 echo "============================="
135 echo "扫描结果汇总 (反向DNS记录)"
136 echo "============================="
137 echo
138
139 # 确保表格对齐
140 max_ip_len=15 # "IP地址" 标题长度
141 max_domain_len=20 # "域名" 标题长度
142
143 # 读取结果计算最大长度
144 while IFS=, read -r ip domain; do
145 if [ ${#ip} -gt $max_ip_len ]; then
146 max_ip_len=${#ip}
147 fi
148
149 if [ ${#domain} -gt $max_domain_len ]; then
150 max_domain_len=${#domain}
151 fi
152 done < "$RESULT_FILE"
153
154 # 添加边距
155 max_ip_len=$((max_ip_len + 2))
156 max_domain_len=$((max_domain_len + 2))
157 if [ $max_ip_len -lt 15 ]; then max_ip_len=15; fi
158 if [ $max_domain_len -lt 20 ]; then max_domain_len=20; fi
159
160 # 创建表格顶部
161 printf "┌─%s─┬─%s─┐\n" "$(printf '%*s' "$max_ip_len" "" | tr ' ' '-')" \
162 "$(printf '%*s' "$max_domain_len" "" | tr ' ' '-')"
163
164 # 表格标题
165 printf "│ %-${max_ip_len}s │ %-${max_domain_len}s │\n" "IP地址" "域名"
166 printf "├─%s─┼─%s─┤\n" "$(printf '%*s' "$max_ip_len" "" | tr ' ' '-')" \
167 "$(printf '%*s' "$max_domain_len" "" | tr ' ' '-')"
168
169 # 表格内容
170 while IFS=, read -r ip domain; do
171 printf "│ %-${max_ip_len}s │ %-${max_domain_len}s │\n" "$ip" "$domain"
172 done < "$RESULT_FILE"
173
174 # 表格底部
175 printf "└─%s─┴─%s─┘\n" "$(printf '%*s' "$max_ip_len" "" | tr ' ' '-')" \
176 "$(printf '%*s' "$max_domain_len" "" | tr ' ' '-')"
177 echo
178fi
179
180# 输出统计信息
181echo "============================="
182echo "扫描完成"
183echo "结束时间: $(date)"
184echo "总耗时: $((TOTAL_TIME / 60)) 分钟 $((TOTAL_TIME % 60)) 秒"
185echo "共扫描: $COUNT 个IP地址"
186echo "发现: $FOUND 个反向DNS记录"
187echo "CSV文件: $CSV_OUTPUT"
188echo "============================="
189
190# 清理临时文件
191rm -f "$RESULT_FILE"
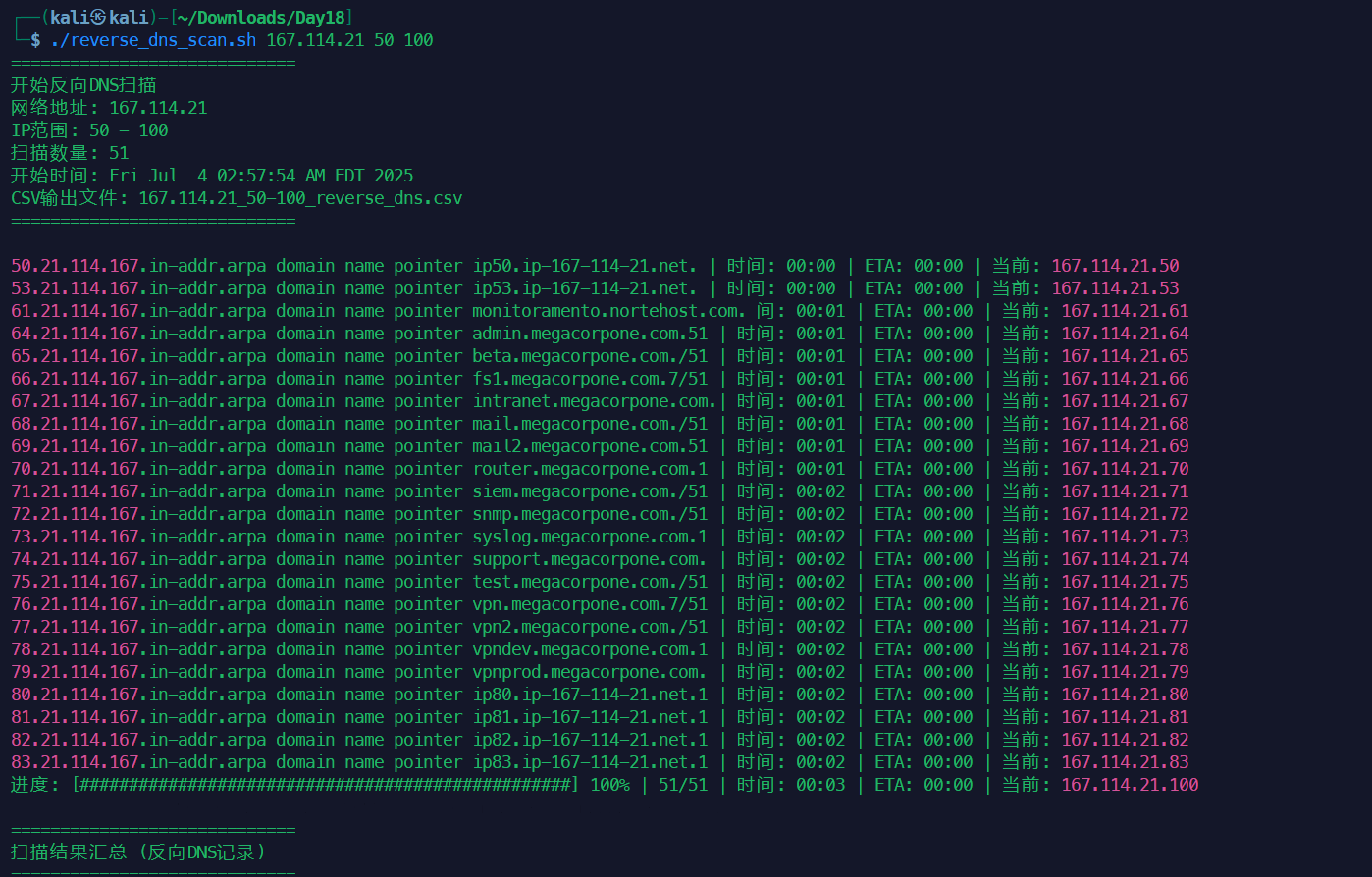
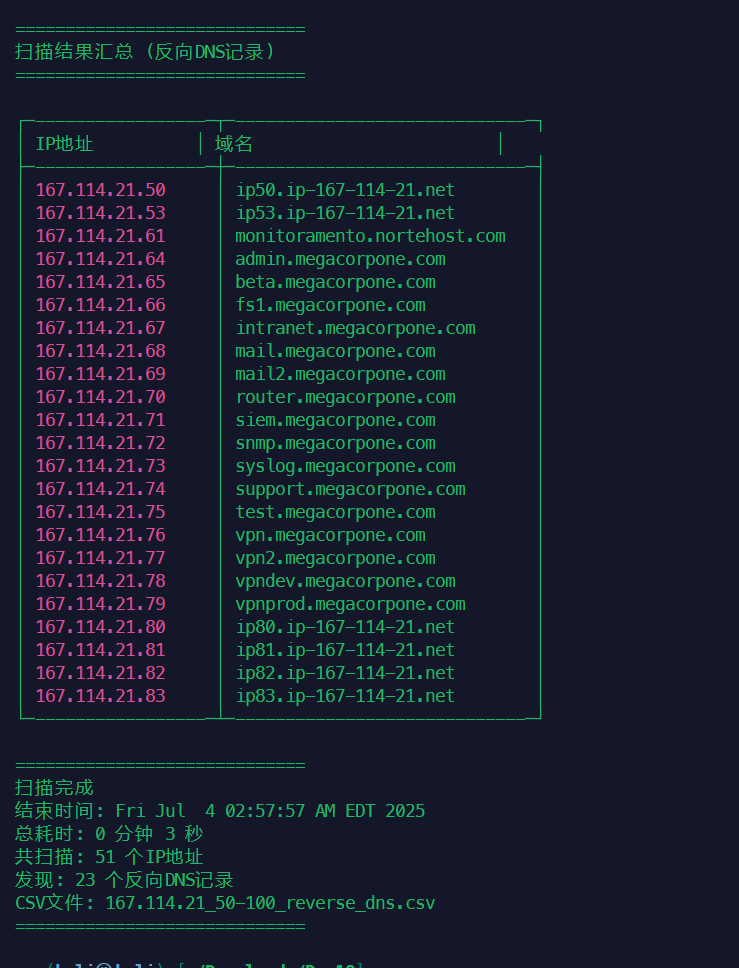
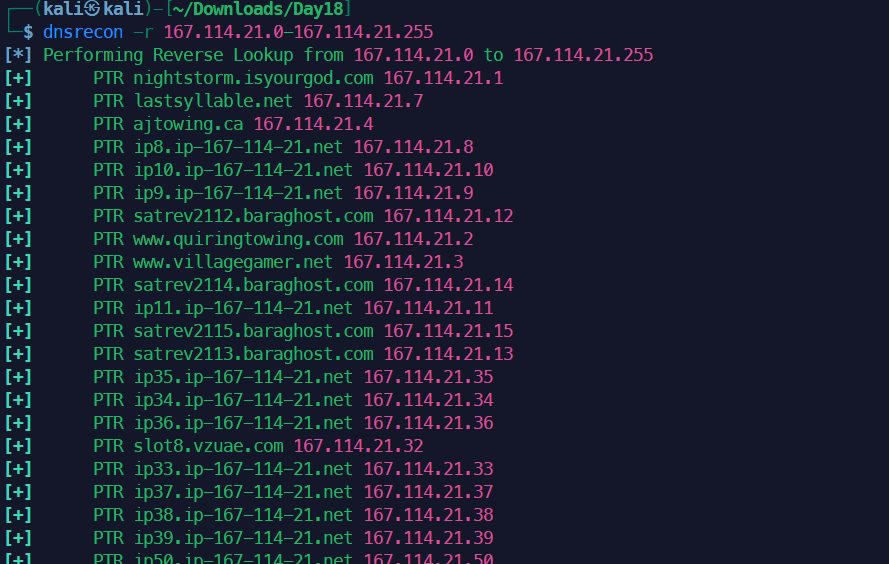
对比可以发现,反向查找出来了一些正向用字典没又找到的子域名。
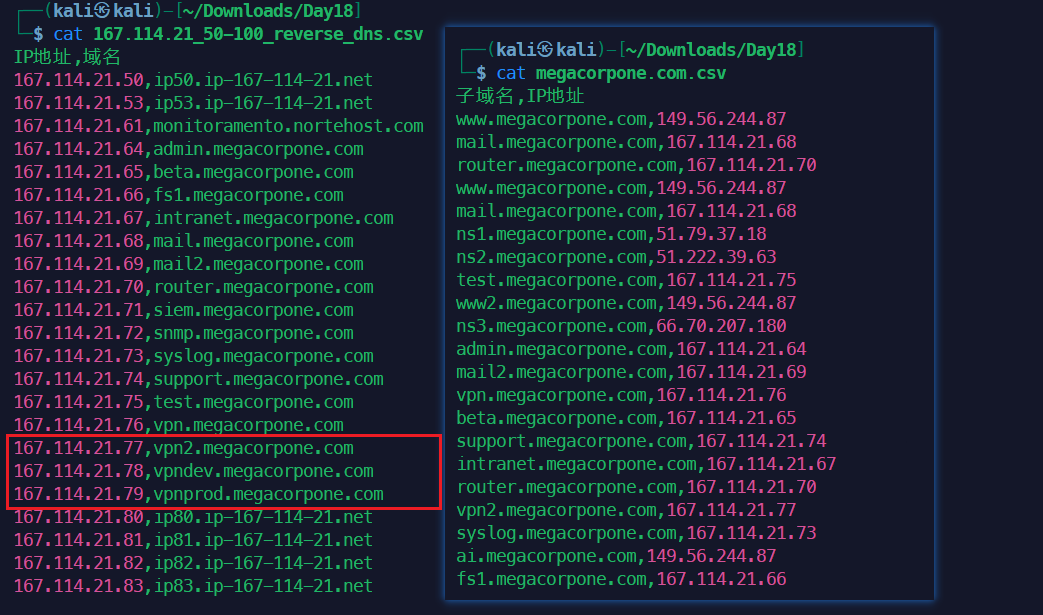
用命令来辅助我们发现新域名,这些新域名,新IP中可能包含易于攻击的系统。
1comm -13 \
2 <(awk -F, 'NR>1{print $1}' megacorpone.com.csv | sort -u) \
3 <(awk -F, 'NR>1 && $2~/megacorpone\.com$/{print $2}' 167.114.21_50-100_reverse_dns.csv | sort -u) \
4| xargs -I{} grep -i ",{}$" 167.114.21_50-100_reverse_dns.csv \
5| column -t -s, -N "IP地址,域名"
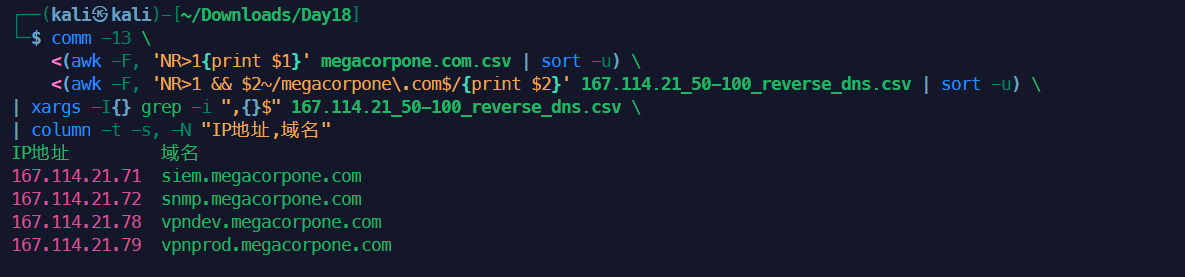
对两个CSV细致分析的还可以用下面这个脚本
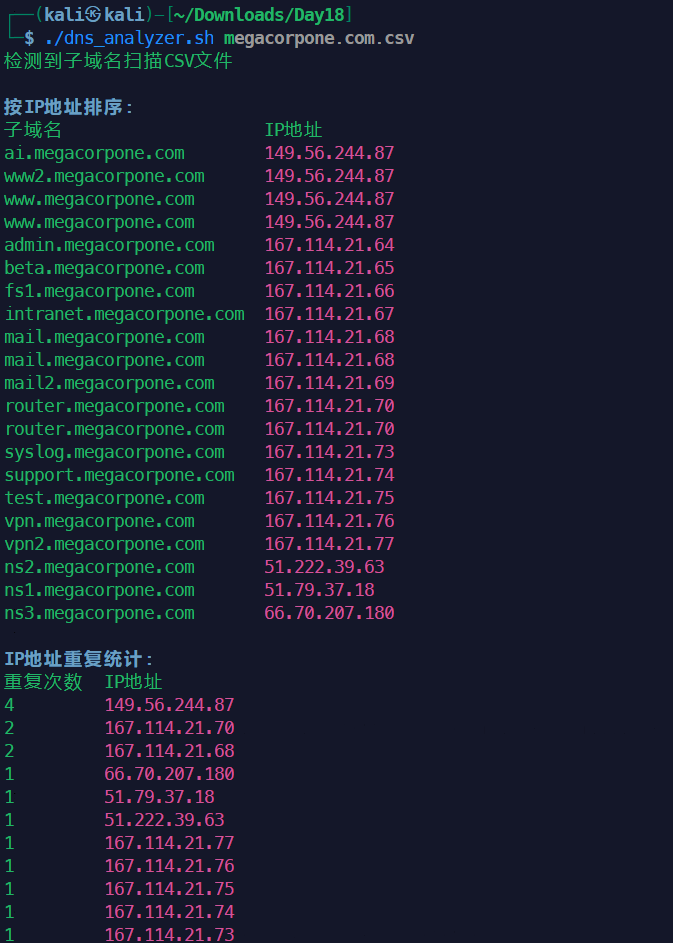
1#!/bin/bash
2# 脚本名称: dns_analyzer.sh
3# 功能: 智能分析DNS扫描CSV文件,支持子域名统计和反向DNS统计
4# 用法: ./dns_analyzer.sh 输入文件.csv
5
6# 错误处理
7die() {
8 echo "错误: $1" >&2
9 exit 1
10}
11
12# 检查参数
13if [ $# -ne 1 ]; then
14 die "用法: $0 输入文件.csv"
15fi
16
17INPUT_FILE="$1"
18if [ ! -f "$INPUT_FILE" ]; then
19 die "文件不存在: $INPUT_FILE"
20fi
21
22# 检测文件类型
23if head -1 "$INPUT_FILE" | grep -qE "子域名,IP地址|subdomain,ip"; then
24 echo "检测到子域名扫描CSV文件"
25 FILE_TYPE="subdomain"
26elif head -1 "$INPUT_FILE" | grep -qE "IP地址,域名|ip,domain"; then
27 echo "检测到反向DNS扫描CSV文件"
28 FILE_TYPE="reverse"
29else
30 die "无法识别CSV文件类型 - 请确保文件包含正确的标题行"
31fi
32
33# 美观的域名列表输出函数
34pretty_print_domains() {
35 local domains="$1"
36 local max_length=0
37 local count=0
38
39 # 将域名拆分为数组
40 IFS=',' read -ra DOMAIN_ARRAY <<< "$domains"
41 count=${#DOMAIN_ARRAY[@]}
42
43 # 计算最大域名长度
44 for domain in "${DOMAIN_ARRAY[@]}"; do
45 domain=$(echo "$domain" | xargs) # 去除前后空格
46 len=${#domain}
47 if (( len > max_length )); then
48 max_length=$len
49 fi
50 done
51
52 # 计算列数和每列宽度
53 local columns=$(( $(tput cols) / (max_length + 4) ))
54 if (( columns < 1 )); then columns=1; fi
55 if (( columns > 6 )); then columns=6; fi
56
57 # 计算行数
58 local rows=$(( (count + columns - 1) / columns ))
59
60 # 格式化输出
61 echo
62 for (( i=0; i<rows; i++ )); do
63 printf " "
64 for (( j=0; j<columns; j++ )); do
65 idx=$(( i + j * rows ))
66 if (( idx < count )); then
67 domain=$(echo "${DOMAIN_ARRAY[$idx]}" | xargs)
68 printf "%-*s" $((max_length + 4)) "$domain"
69 fi
70 done
71 echo
72 done
73 echo
74}
75
76# 处理子域名文件
77process_subdomain() {
78 local file="$1"
79
80 # 按IP排序
81 echo -e "\n\033[1;34m按IP地址排序:\033[0m"
82 awk -F, 'NR>1' "$file" | sort -t, -k2 | column -t -s, -N "子域名,IP地址"
83
84 # IP重复统计
85 echo -e "\n\033[1;34mIP地址重复统计:\033[0m"
86 awk -F, 'NR>1 {ip_count[$2]++} END {
87 for (ip in ip_count) {
88 printf "%d\t%s\n", ip_count[ip], ip
89 }
90 }' "$file" | sort -nr | column -t -N "重复次数,IP地址"
91
92 # 重复最多的IP
93 echo -e "\n\033[1;34m重复最多的IP地址:\033[0m"
94 awk -F, 'NR>1 {ip_count[$2]++} END {
95 max_count = 0
96 for (ip in ip_count) {
97 if (ip_count[ip] > max_count) {
98 max_count = ip_count[ip]
99 max_ip = ip
100 }
101 }
102 printf "IP地址: %s\n重复次数: %d\n", max_ip, max_count
103 }' "$file"
104}
105
106# 处理反向DNS文件
107process_reverse() {
108 local file="$1"
109
110 # 主域名统计
111 echo -e "\n\033[1;34m主域名出现统计:\033[0m"
112 awk -F, 'NR>1 && $2 != "" {
113 # 提取主域名
114 n = split($2, parts, ".")
115 if (n > 1) {
116 main_domain = parts[n-1] "." parts[n]
117 domain_count[main_domain]++
118 }
119 } END {
120 for (d in domain_count) {
121 printf "%d\t%s\n", domain_count[d], d
122 }
123 }' "$file" | sort -nr | column -t -N "出现次数,主域名"
124
125 # 重复最多的主域名
126 echo -e "\n\033[1;34m重复最多的主域名:\033[0m"
127 awk -F, 'NR>1 && $2 != "" {
128 n = split($2, parts, ".")
129 if (n > 1) {
130 main_domain = parts[n-1] "." parts[n]
131 domain_count[main_domain]++
132 }
133 } END {
134 max_count = 0
135 for (d in domain_count) {
136 if (domain_count[d] > max_count) {
137 max_count = domain_count[d]
138 max_domain = d
139 }
140 }
141 printf "主域名: %s\n出现次数: %d\n", max_domain, max_count
142 }' "$file"
143
144 # 主域名关联的完整域名(美观格式)
145 echo -e "\n\033[1;34m主域名关联的完整域名:\033[0m"
146 awk -F, 'BEGIN {print "开始收集域名..."}
147 NR>1 && $2 != "" {
148 n = split($2, parts, ".")
149 if (n > 1) {
150 main_domain = parts[n-1] "." parts[n]
151 if (!(main_domain in domain_list)) {
152 domain_list[main_domain] = $2
153 } else {
154 domain_list[main_domain] = domain_list[main_domain] "," $2
155 }
156 # print "收集: " $2 " -> " main_domain
157 }
158 } END {
159 print "收集完成,开始输出..."
160 for (d in domain_list) {
161 printf "%s:%s\n", d, domain_list[d]
162 }
163 }' "$file" > /tmp/domain_groups.txt
164
165 while IFS=: read -r domain_group domains; do
166 echo -e "\033[1;32m$domain_group:\033[0m"
167 pretty_print_domains "$domains"
168 done < /tmp/domain_groups.txt
169 rm -f /tmp/domain_groups.txt
170}
171
172# 根据文件类型执行相应处理
173case "$FILE_TYPE" in
174 subdomain)
175 process_subdomain "$INPUT_FILE"
176 ;;
177 reverse)
178 process_reverse "$INPUT_FILE"
179 ;;
180 *)
181 die "未知文件类型"
182 ;;
183esac
184
185echo -e "\n\033[1;32m分析完成!\033[0m"
区域传输
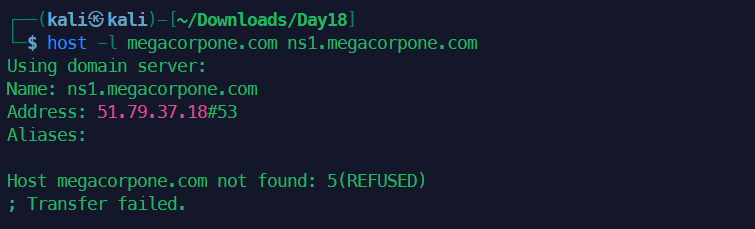
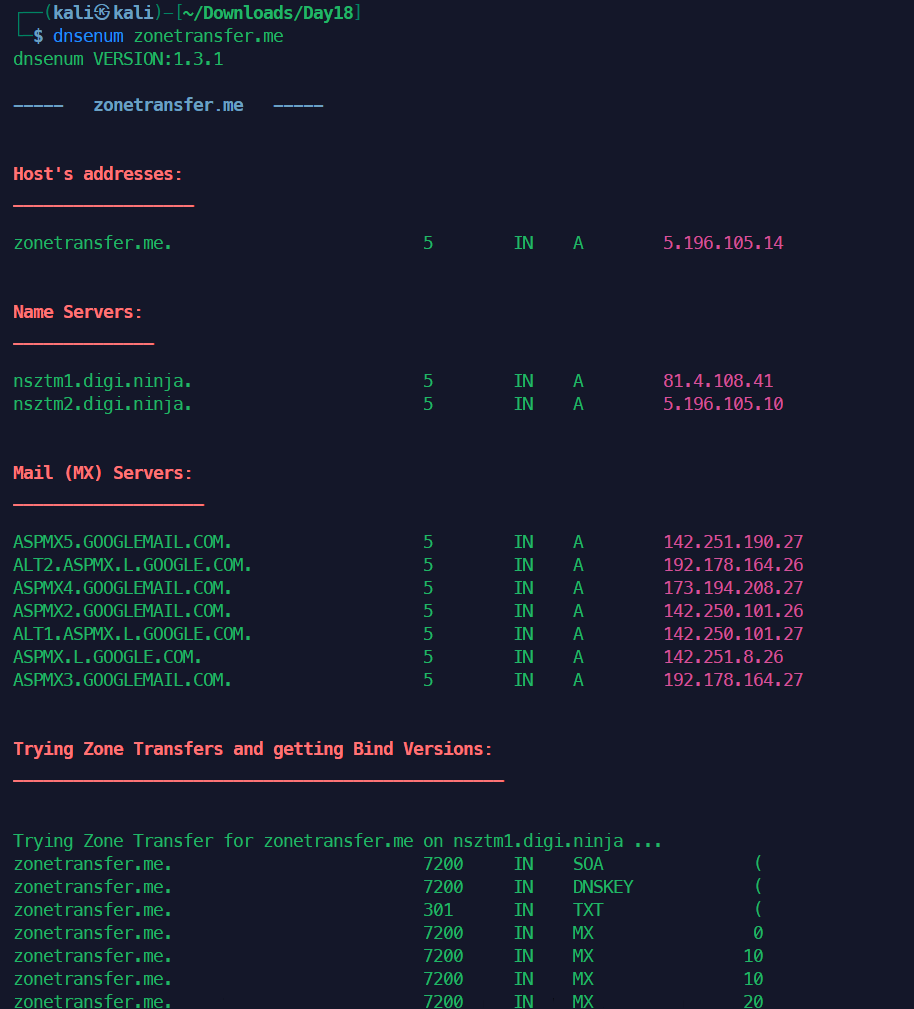
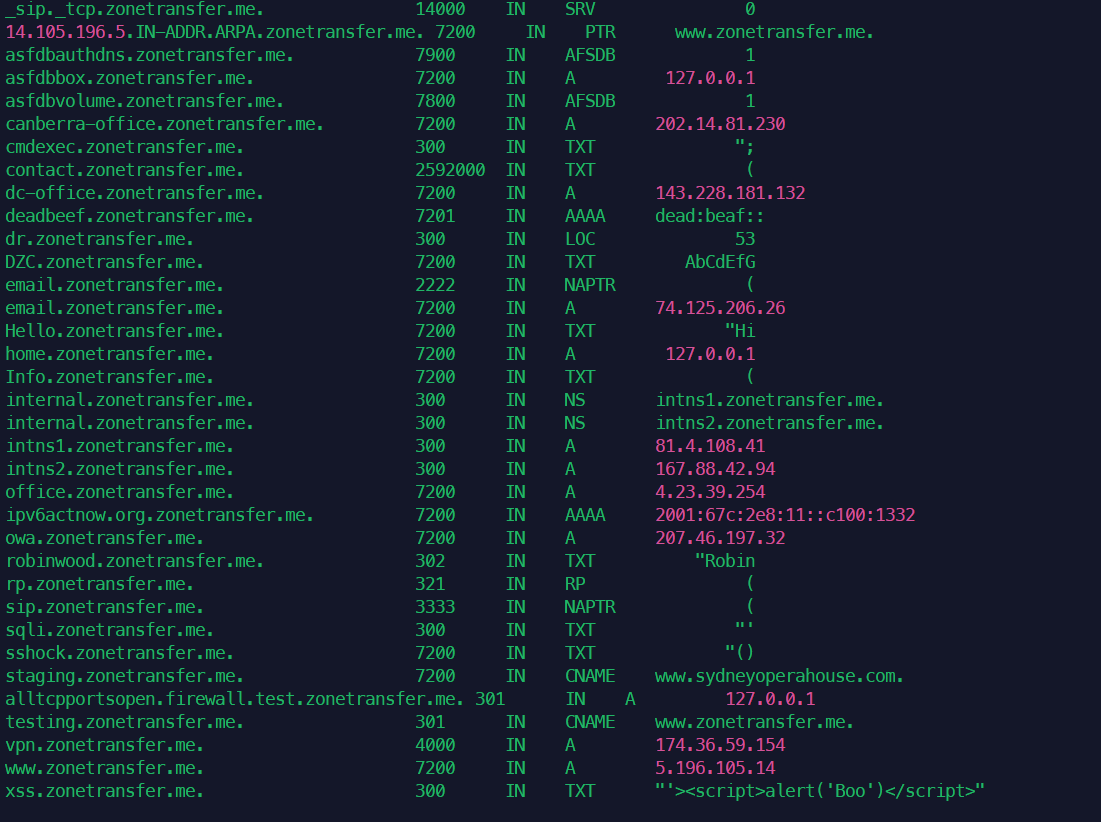
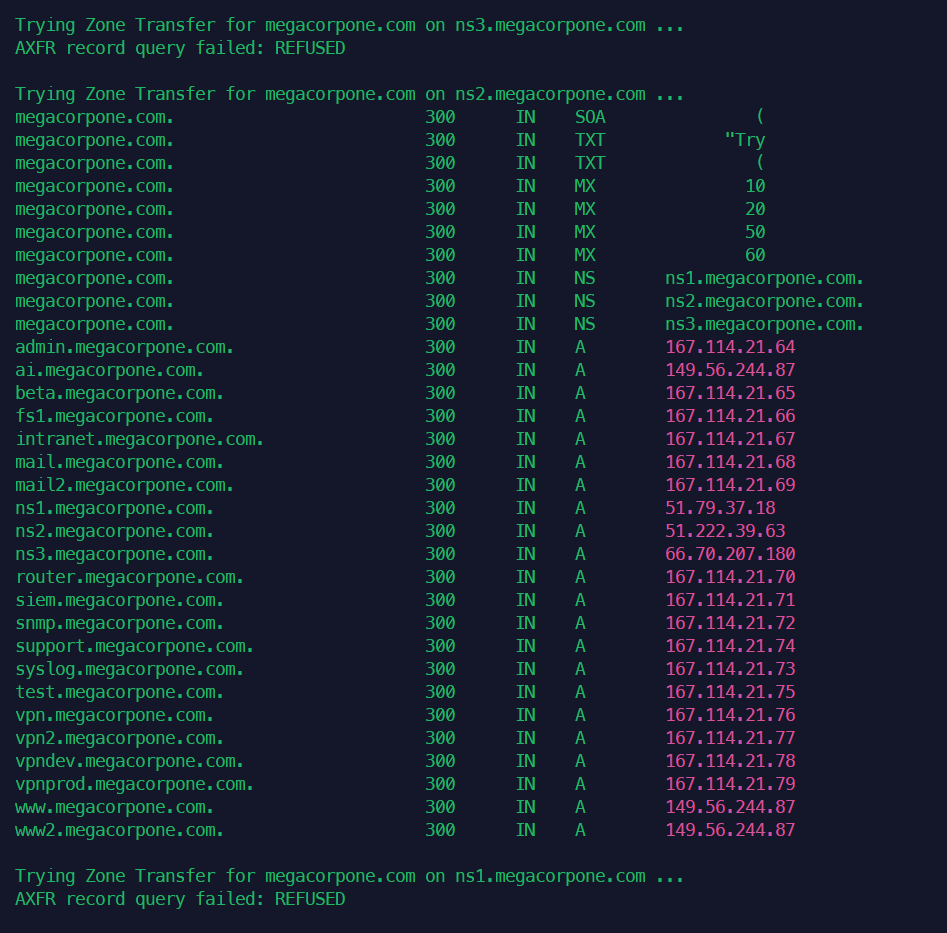
DNS区域传输基本上是相关DNS服务器之间的数据库复制,其中区域文件从主DNS服务器复制到从DNS服务器。区域文件包含所有DNS的列表为该区域配置的名称。区域传输应该只允许授权的从DNS但是许多管理员错误地配置了他们的DNS服务器,在这些情况下,任何人都问DNS服务器区域通常会收到一个副本。这相当于把公司的网络布局放在硬盘上交给黑客。所有的名字,服务器的地址和功能可能会暴露在窥探者的视线之下。成功的区域传输不会直接导致网络破坏,尽管它确实有助于这个过程(主要是信息泄露)。执行分区传输的host命令语法如下:
1host -l megacorpone.com ns1.megacorpone.com
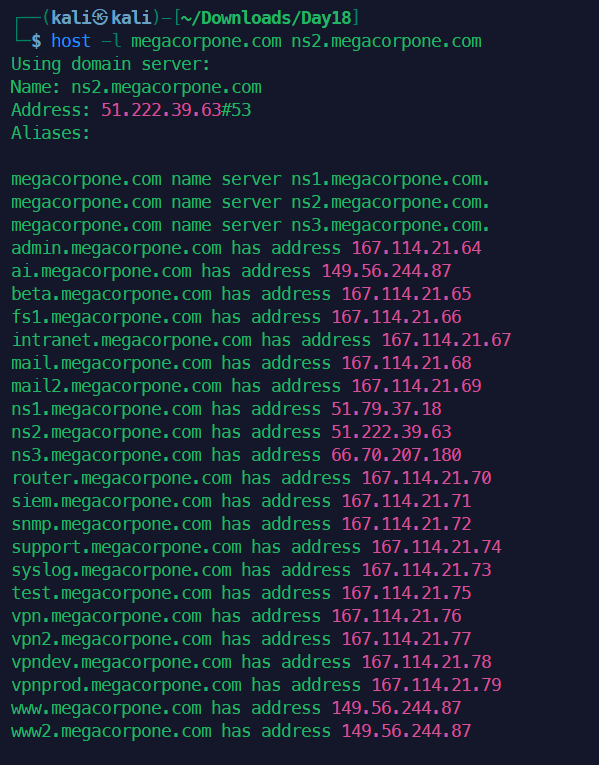
可以看到ns2是有区域传输漏洞的。
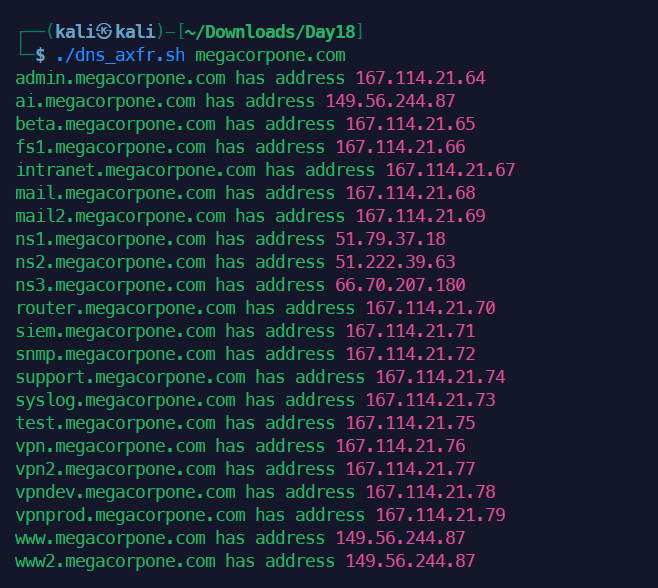
此服务器允许区域传输,并提供区域文件的完整转储megacorpone.com域名,提供方便的IP地址列表和相应的DNS主机名! megacorpone.com域需要检查的DNS服务器非常少。然而,一些较大的组织可能托管许多DNS服务器,或者我们可能想要尝试区域传输请求针对给定域中的所有DNS服务器。Bash脚本可以帮助完成这项任务。要尝试使用host命令进行区域传输,我们需要两个参数:名称服务器地址和域名。我们可以使用以下命令获取给定域的名称服务器命令:
1host -t ns megacorpone.com | cut -d " " -f 4
1#!/bin/bash
2# Simple Zone Transfer Bash Script
3# $1 is the first argument given after the bash script
4# Check if argument was given, if not, print usage
5if [ -z "$1" ]; then
6 echo "[*] Simple Zone transfer script"
7 echo "[*] Usage : $0 <domain name> "
8 exit 0
9fi
10# if argument was given, identify the DNS servers for the domain
11for server in $(host -t ns $1 | cut -d " " -f4); do
12 # For each of these servers, attempt a zone transfer
13 host -l $1 $server |grep "has address"
14done
Kali自带的DNS枚举工具
DNSrecon
1sudo apt update && sudo apt install dnsrecon -y
2dnsrecon -h
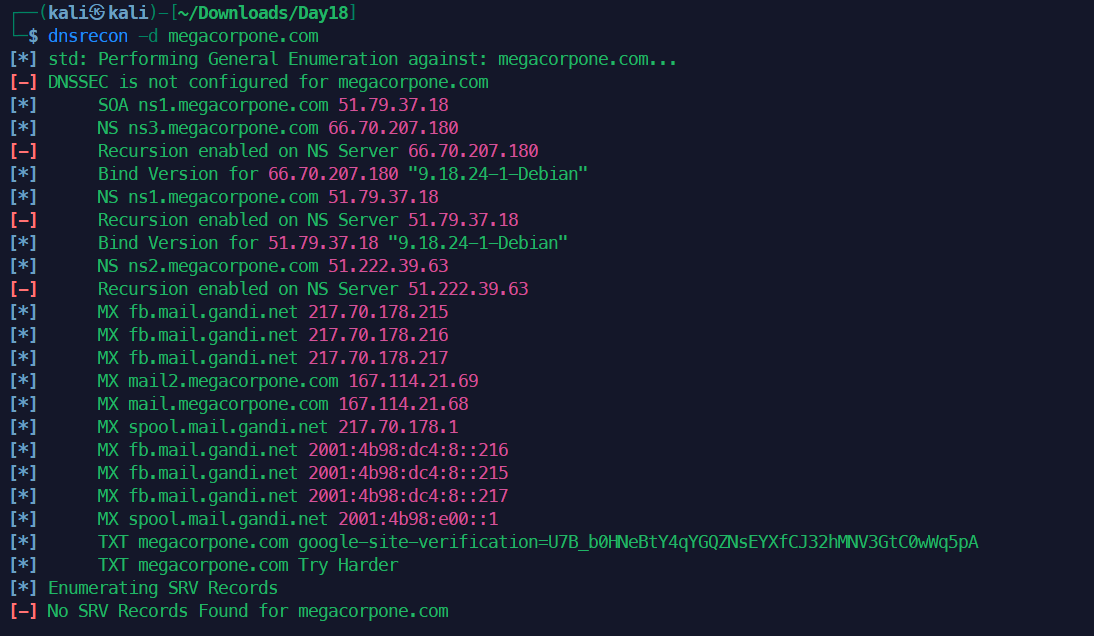
3dnsrecon -d megacorpone.com
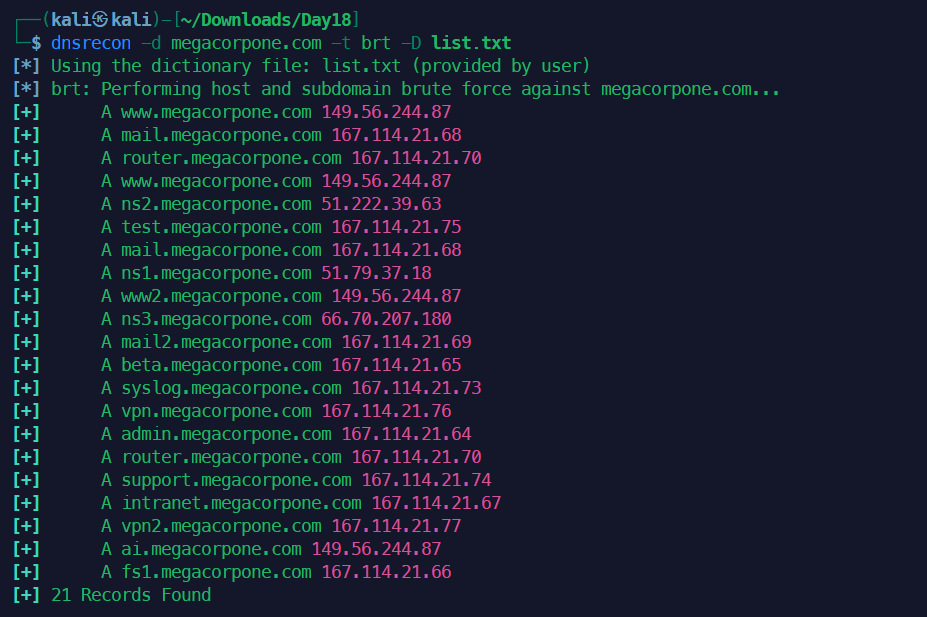
4dnsrecon -d megacorpone.com -t brt -D /usr/share/seclists/Discovery/DNS/subdomains-top1million-5000.txt # 子域名暴力破解
5dnsrecon -r 167.114.21.0-167.114.21.255 # 反向爆破
6dnsrecon -d megacorpone.com -t axfr # 区域传送漏洞检测
DNSenum
1dnsenum zonetransfer.me
2dnsenum -f /usr/share/wordlists/dnsmap.txt megacorpone.com
3dnsenum -f /usr/share/seclists/Discovery/DNS/subdomains-top1million-5000.txt megacorpone.com
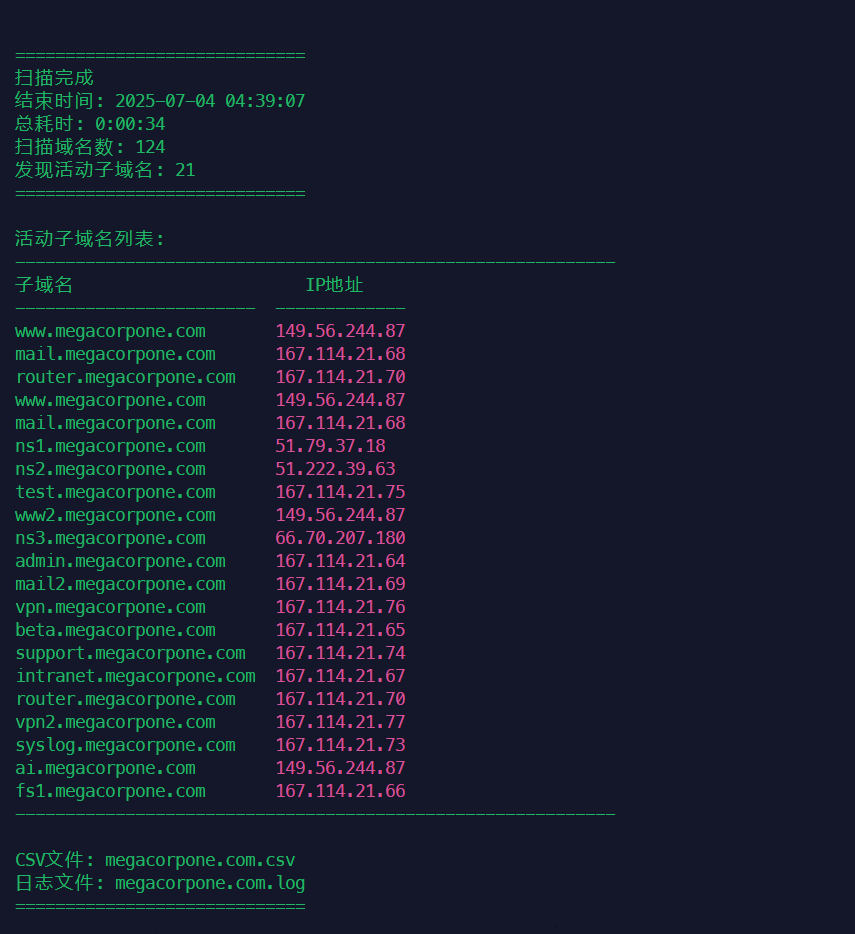
7.1.6.3练习
- 查找megacorpone.com域的DNS服务器。
- 编写一个小脚本,尝试使用更高级别从megacorpone.com进行区域传输,脚本语言,如Python、Perl或Ruby。
- 重新创建上面的示例,并使用dnsrecon尝试从megacorpone.com。
2.改写小脚本
完整脚本可以关注我公众号后台回复关键字领取。
python使用示例:
# 基本用法
python3 subdomain_finder.py megacorpone.com
# 自定义字典和输出
python3 subdomain_finder.py megacorpone.com \
-w custom.txt \
-o results.csv
端口扫描
端口扫描是检查远程计算机上的TCP或UDP端口的过程,目的是检测目标上正在运行的服务以及可能存在的潜在攻击媒介。
在一些网络基础设施落后的国家,简单的扫描就有可能导致网站崩溃(DDOS),所以一些国家将扫描视为违法行为。在中国大多数云服务器都能抗住普通扫描的流量。
TCP/UDP扫描使用NC
TCP扫描
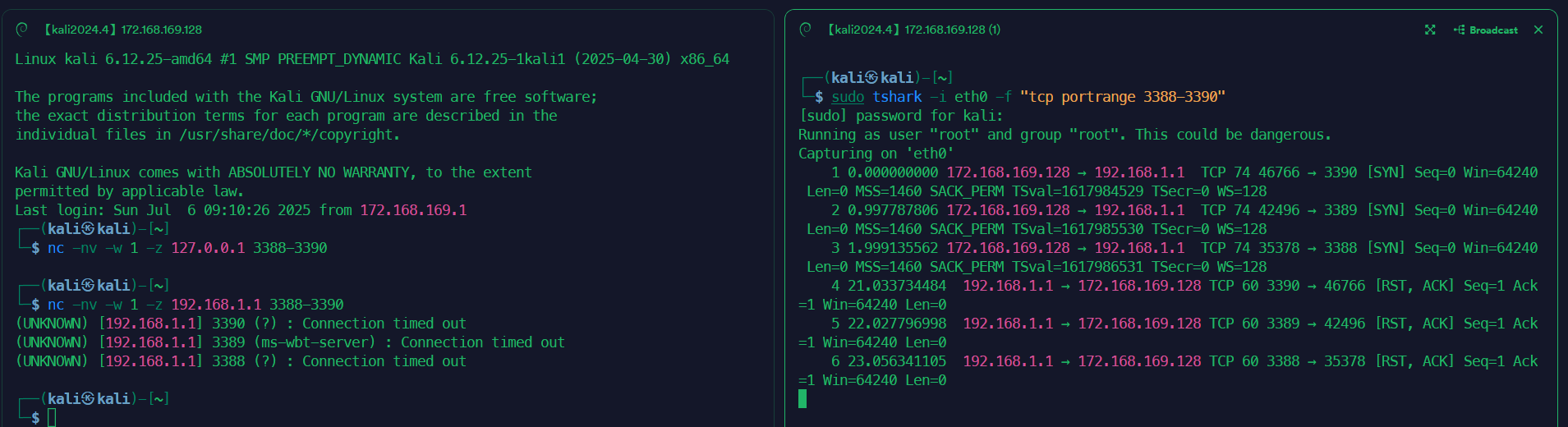
最简单的TCP端口扫描技术通常称为CONNECT扫描,它依赖于三向TCP握手195机制。设计此机制是为了使两个尝试进行通信的主机可以在传输任何数据之前协商网络TCP套接字连接的参数。在没有专门的扫描工具的时候,也可以使用Netcat来改造一下。
1 nc -nv -w 1 -z 192.168.1.1 3388-3390
2 sudo tshark -i eth0 -f "tcp portrange 3388-3390"
UDP扫描
由于UDP是无状态的,并且不涉及三向握手,因此UDP端口扫描的机制不同于TCP。udp是无状态尽力传输协议,没有三次握手机制,使用针对协议的udp扫描提高准确度,发送udp空包,端口开放服务器无响应,端口关闭返回icmp端口不可达。此机制扫描结果不完全准确,但是很多攻击向量(应用处理异常,FW过滤icmp包),而且nc很小,主要是在内网收到限制的时候使用。
1nc -nv -u -z -w 1 192.168.1.1 160-162
2sudo tshark -i eth0 -f "udp portrange 160-162"

Nmap端口扫描
虽然Nmap扫描功能很强大,但是很多的nmap扫描选项需要访问 raw sockets,因此需要sudo执行,否则扫描能力受限。很多防火墙都对Nmap做了限制。
对防火墙设置一些规则,来观察Nmap产生的流量有多大。
步骤 1:设置防火墙规则(允许特定 IP 通行)
sudo iptables -I INPUT 1 -s 38.100.193.70 -j ACCEPT
sudo iptables -I OUTPUT 1 -d 38.100.193.70 -j ACCEPT
作用:
- 允许来自
38.100.193.70的入站流量(INPUT链)。 - 允许发送到
38.100.193.70的出站流量(OUTPUT链)。
- 允许来自
目的:确保后续
nmap扫描不会被防火墙拦截,同时防火墙会记录流量统计。注意38.100.193.70是OSCP官方给的练手网站的IP地址,这个IP是会变动的,请根据host的结果调整。
步骤 2:重置防火墙计数器
sudo iptables -Z
- 作用:清零所有
iptables规则的流量计数器(包数pkts和字节数bytes)。 - 目的:为后续扫描流量统计做准备,确保计数从零开始。
步骤 3:执行第一次端口扫描(默认扫描)
sudo nmap 38.100.193.70
- 作用:扫描目标 IP 的 常用 1000 个端口。
- 目的:触发与目标 IP 的网络通信,防火墙会记录流量。
步骤 4:查看流量统计(第一次)
sudo iptables -vn -L
作用:查看防火墙规则详情:
-v:显示详细计数(包数、字节数)。
-n:不解析 IP 和端口(直接显示数字)。

步骤 5:再次重置计数器
sudo iptables -Z
- 目的:为第二次扫描准备干净的计数起点。
步骤 6:执行第二次端口扫描(全端口扫描)
nmap -p- 38.100.193.70
- 作用:扫描目标 IP 的 全端口(1-65535),此操作耗时较长(约 10-30 分钟)。
- 目的:触发更大规模的流量,对比两次扫描的流量差异。
步骤 7:查看最终流量统计
sudo iptables -vn -L
作用:显示第二次扫描后的流量统计。
目的:
比较
pkts和bytes与第一次扫描的差异(全端口扫描的流量更大)。验证防火墙规则是否正确捕获流量。
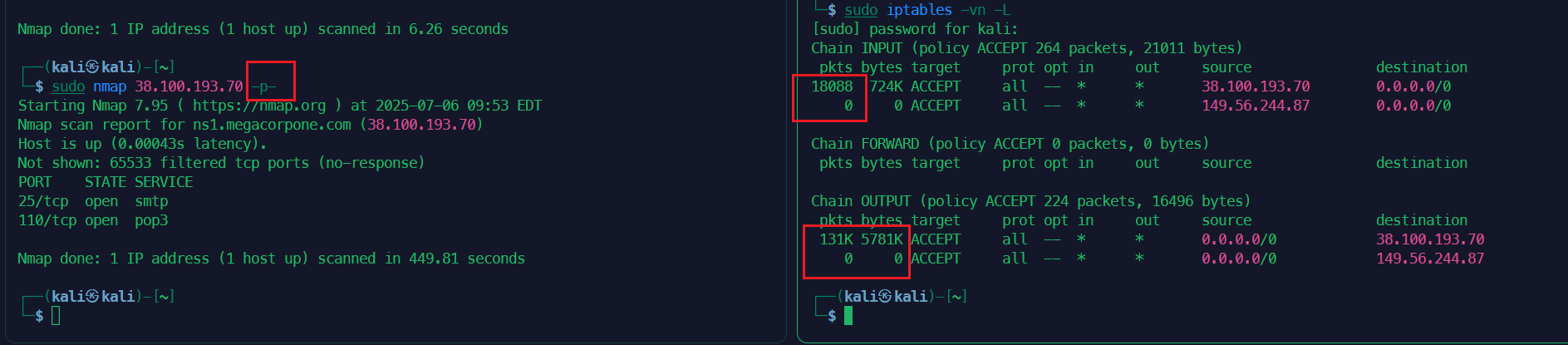
结束后清理规则
# 删除添加的规则(避免影响后续操作)
sudo iptables -D INPUT -s 38.100.193.70 -j ACCEPT
sudo iptables -D OUTPUT -d 38.100.193.70 -j ACCEPT
C段全端口扫描大约消耗1gb流量,大段扫描的时候应该考虑带宽、速度、流量等问题。如果大量的去扫,还没有挂代理池的情况下,你短时间目标防火墙接搜到一个G的流量,百分百会反制封锁你的IP地址。一般扫描,最好挂代理,或者IP伪造(治标不治本),在这种情况下才可以做大量的暴力扫描,不然很容易出事。

Nmap的SYN“隐蔽”扫描
Nmap默认使用SYN扫描,不完成三次握手,信息未达应用层,不产生应用层日志(网络层检测),快速。现代防火墙普遍具有半开连接的检测能力,所谓的隐蔽扫描,一点都不隐蔽,反倒是对小白有误导。
1. 什么是 SYN 扫描 (-sS)?
TCP 连接建立基础:
正常的 TCP 连接需要完成“三次握手”:
- 客户端 -> 服务器:发送
SYN包 (请求建立连接) - 服务器 -> 客户端:发送
SYN-ACK包 (同意建立连接) - 客户端 -> 服务器:发送
ACK包 (确认连接建立,数据可开始传输)
- 客户端 -> 服务器:发送
SYN 扫描的原理:
- Nmap 扮演客户端,向目标端口发送一个伪造源地址的
SYN包 (第 1 步)。 - 如果目标端口 开放:目标主机会回应一个
SYN-ACK包 (第 2 步)。 - 关键点来了:Nmap 看到
SYN-ACK回应后,不会发送完成握手的ACK包 (第 3 步)!相反,它发送一个RST(复位) 包来立即终止这个半开的连接。 - 如果目标端口 关闭:目标主机会回应一个
RST包。 - 如果目标端口 被过滤(防火墙拦截):Nmap 通常收不到任何回应,或者收到 ICMP 错误消息。
- Nmap 扮演客户端,向目标端口发送一个伪造源地址的
为何在应用层“隐蔽”:
- 由于 Nmap 没有发送最后的
ACK来完成握手,TCP 连接从未真正建立。 - 因此,目标端口上监听的应用程序服务程序(如 Web 服务器、数据库服务)根本没有被激活。操作系统内核的网络协议栈在处理到 SYN-ACK 回复这一步后就因为收到 RST 而终止连接。
- 结果:应用层日志里通常找不到这次扫描的记录。 应用服务完全不知道有人尝试连接过。
- 由于 Nmap 没有发送最后的
2. 为何“对小白有误导”?为什么说“一点都不隐蔽”?
虽然 SYN 扫描避开了应用层日志,但这并不意味着它在网络层面是隐蔽的或不留下痕迹。主要的误导在于初学者可能会认为“不在应用日志里 == 完全隐身”。这是错误的认知。
- 现代防火墙/IDS/IPS 的检测能力:
- 状态检测 (Stateful Inspection): 这是现代防火墙最基本、最核心的功能之一。防火墙会跟踪所有连接的状态。当它看到一个进来的
SYN包,但随后看到的是客户端的RST包(而不是正常的ACK)时,它就知道这个连接没有完成正常的三次握手。这是一个非常明显的异常行为特征。 - 检测 SYN 扫描模式: 高级安全设备会分析网络流量模式。短时间内(几秒或几分钟内)向大量不同端口发送
SYN包,并且每个连接都停留在“半开”状态(即没有后续的ACK),这极其符合 SYN 端口扫描的特征模式。安全设备可以很容易地通过这种流量特征或速率检测出扫描行为。 - 记录和告警: 虽然应用层服务没日志,但防火墙、入侵检测系统 (IDS)、入侵防御系统 (IPS) 和专业的网络安全监控 (NSM) 平台非常擅长检测、记录和产生大量的告警来报告 SYN 扫描活动。这些日志和告警通常包含源 IP、时间戳、扫描的端口数量等信息。
- 生成“防火墙日志”: 防火墙会记录这些被检测到的扫描包(丢弃的或被接受的半开连接),而这些日志是网络管理员和安全分析师最常查看的地方。
- 状态检测 (Stateful Inspection): 这是现代防火墙最基本、最核心的功能之一。防火墙会跟踪所有连接的状态。当它看到一个进来的
- 总结 “一点都不隐蔽”: 虽然 SYN 扫描避开了最表层(应用日志),但它在网络层/传输层留下了极其清晰、易于被现代安全设备识别的特征指纹。在稍有安全防护措施的网络中,这样的扫描就像是黑夜里点燃的信号弹一样明显。安全运维人员第一时间就能看到防火墙或 SIEM 系统发出的 SYN Flood 或端口扫描告警。
3. 怎么达到(相对)隐蔽的目的?
绝对的隐蔽在互联网扫描中几乎是不可能的。防御方有多种手段(流量监控、蜜罐、ISP 合作等)来检测扫描活动。我们的目标通常是降低检测率、减少告警噪音、延缓被发现的时间、避免被轻易追踪或封禁。一些更隐蔽的扫描技术包括:
FIN扫描 (-sF),NULL扫描 (-sN),Xmas扫描 (-sX):- 原理: 利用 TCP RFC 规定的一个“小漏洞”:当一个关闭的端口收到不携带 SYN、ACK 或 RST 标志位的怪异包(如只带 FIN、只带 NULL 标志、或者组合了 FIN/URG/PSH 像圣诞树灯一样 - 故名 Xmas)时,应该回复一个
RST包。而开放的端口则应该忽略这种不符合连接状态的包,不回复。 - 相对隐蔽性: 这种扫描不会尝试建立连接(没有 SYN 包),不是半开连接。它们更像是“敲门试探”。状态防火墙跟踪连接状态时,这些包属于不连接任何现有流量的“异常包”,更难以被仅依赖状态检测的设备识别为扫描(虽然专门检测端口扫描的设备仍然可能抓到)。它们模仿的是连接关闭后残留的迷途包。
- 局限性: 很多非 Unix 系统(如 Windows)的 TCP 栈不严格遵守 RFC,无论端口开放与否,都一律回复 RST。这使得这些扫描对 Windows 主机无效。效果高度依赖于目标系统实现。
- 原理: 利用 TCP RFC 规定的一个“小漏洞”:当一个关闭的端口收到不携带 SYN、ACK 或 RST 标志位的怪异包(如只带 FIN、只带 NULL 标志、或者组合了 FIN/URG/PSH 像圣诞树灯一样 - 故名 Xmas)时,应该回复一个
ACK扫描 (-sA):- 原理: 只发送一个设置了
ACK位的 TCP 包(通常这是三次握手之后的数据包才会有的标志)。不开放端口的防火墙或无状态防火墙会允许 ACK 到达主机,主机根据本地连接状态(肯定没有这个连接)回复一个RST。而开放端口且配置了严格状态防火墙的服务器可能会直接丢弃这个 ACK,或者服务器回复 RST 但防火墙阻止了(取决于防火墙规则)。 - 目的: 主要用于探测目标主机防火墙的状态和规则(是否有状态检测?是否过滤入站包?是否屏蔽特定端口?),而不是直接判断端口开放与否(虽然可以通过是否有 RST 回复间接推断端口是否被防火墙过滤)。本身不那么像端口扫描,更像是网络设备探测。
- 相对隐蔽性: 单个 ACK 包在大量合法流量中不太起眼。不易被简单的 SYN 扫描检测规则发现。
- 原理: 只发送一个设置了
Idle/ Zombie 扫描 (-sI):- 原理: 这是最隐蔽的扫描技术之一。利用一个网络上的空闲主机(僵尸/Zombie)的 IP 标识值 (IP ID) 来间接推断目标端口的开放状态。整个过程 Nmap 自身 IP 完全不直接与目标主机通信,所有通信都由 Zombie 发起(或对 Zombie 发起的伪造包做出响应)。
- 相对隐蔽性: 极高的隐蔽性。目标主机看到的扫描来源是 Zombie 主机,而不是你的扫描机(源 IP 欺骗)。目标主机与 Zombie 主机之间的交互(探测包)更像是正常的、零星的网络试探。
- 复杂性和局限性: 实施非常复杂(需要找到合适的 Zombie 主机,其 IP ID 需是可预测增长的),成功率受很多因素影响(Zombie 的网络活动、路由过滤等)。效率较低。
- 降低检测率的关键策略 (与扫描技术结合使用):
- 极慢速率 (
--scan-delay,--max-rate): 将扫描速度降至非常低(如每秒甚至每分钟几个包),模仿正常用户的间歇性访问,融入背景噪声。这是最有效的隐蔽手段之一,但耗时极长。 - 分散时间 (
-T): 使用-T 0(Paranoid) 或-T 1(Sneaky) 等最慢的时序模板,人为引入大量随机延迟。 - 诱饵扫描 (
-D): 指定多个诱饵 IP(-D decoy1,decoy2,decoy3,ME)。这样目标会看到来自大量不同 IP 的扫描(包括诱饵和你的真实 IP),增加了追踪真实源的难度。需要诱饵 IP 确实存在且在网络上可达才能有效混淆。 - 源端口伪装 (
-g/--source-port): 使用常见的、被认为合法的源端口(如 HTTP/80, DNS/53),有时可以骗过非常简陋的基于端口号的过滤规则。 - 分片扫描 (
-f,--mtu): 将扫描包分片发送,增加防火墙/IDS 重组和分析内容的难度(但很多设备能重组分片)。 - 使用代理链或 Tor: 通过层层代理或 Tor 网络进行扫描,隐藏扫描源的真实 IP 地址。Tor 出口节点 IP 容易被封禁且扫描速度极慢。
- 极慢速率 (
总结
- SYN 扫描 (
-sS) 原理: 发送 SYN,接收 SYN-ACK 后立即发送 RST,制造“半开连接”,不建立完整连接,避开应用层日志。 - 误导性/不隐蔽: 因其明显的“短时间大量半开连接”特征,极易被现代状态防火墙、IDS/IPS 通过状态跟踪和流量模式分析检测到并告警。它在网络防御层留下的痕迹非常深,对新手造成了“应用层没日志=没人发现”的错误印象。
- (相对)隐蔽方法: 使用非常规扫描类型 (FIN, NULL, Xmas, ACK, Idle/Zombie),并最重要的结合极慢的扫描速率 (
--scan-delay,-T 0/1),辅以诱饵 (-D)、源端口伪装 (-g) 或代理/Tor 等策略。“慢”常常是最大的隐蔽武器。 但记住,没有扫描是真正完全隐形的。
扫描命令:
1sudo nmap 38.100.193.70 -sS
2sudo nmap 38.100.193.70 -sT
3sudo nmap 38.100.193.70 -sU
4sudo nmap 38.100.193.70 -sS -sU
5sudo nmap 38.100.193.70 -sn
6sudo nmap 38.100.193.70 -O
7sudo nmap 38.100.193.70 -sV -A
8sudo nmap 38.100.193.70 --script = smb-os-discovery
9sudo nmap 38.100.193.70 --script = dns-zone-transfer
命令解析
sudo nmap 38.100.193.70 -sS- 作用:TCP SYN 扫描(半开扫描)。
- 原理:发送 SYN 包,收到 SYN-ACK 即判断端口开放(不完成三次握手),速度快且隐蔽(不触发应用层日志)。
- 权限:需要
sudo(需构造原始数据包)。
sudo nmap 38.100.193.70 -sT- 作用:TCP 连接扫描。
- 原理:完成完整的三次握手。速度慢但准确性高,适用于无
sudo权限时,但会触发应用层日志。
sudo nmap 38.100.193.70 -sU- 作用:UDP 扫描。
- 原理:向 UDP 端口发送探测包,通过响应判断状态(如 DNS/DHCP 服务)。速度极慢(UDP 无响应重传机制)。
sudo nmap 38.100.193.70 -sS -sU- 作用:组合 TCP SYN 扫描 + UDP 扫描。
- 用途:全面检测目标机器的 TCP/UDP 开放端口。
sudo nmap 38.100.193.70 -sn- 作用:主机发现(Ping 扫描)。
- 原理:不扫描端口,仅检测目标是否在线(使用 ARP/ICMP/TCP 等协议探测)。
sudo nmap 38.100.193.70 -O- 作用:操作系统指纹识别。
- 原理:通过 TCP/IP 协议栈行为(如 TTL 值、窗口大小)推测目标操作系统。
sudo nmap 38.100.193.70 -sV -A作用:全面扫描组合。
-sV:服务版本探测。-A:启用 OS 识别、版本探测、脚本扫描和路由跟踪。
输出:开放端口、服务版本、操作系统、可能漏洞。
sudo nmap 38.100.193.70 --script=smb-os-discovery- 作用:使用 NSE 脚本
smb-os-discovery获取 Windows/Samba 系统的操作系统信息。 - 用途:识别 SMB 服务的主机名、系统版本等。
- 作用:使用 NSE 脚本
sudo nmap 38.100.193.70 --script=dns-zone-transfer- 作用:使用 NSE 脚本
dns-zone-transfer尝试 DNS 域传送。 - 用途:检测 DNS 服务器配置错误(泄露所有域名记录)。
- 作用:使用 NSE 脚本
推荐组合命令
1. 快速扫描(基础端口 + 服务识别)
sudo nmap -T4 -F -sV 38.100.193.70
-T4:高速模式(牺牲隐蔽性换速度)。-F:扫描前 100 个常见端口。-sV:探测服务版本。- 用途:快速获取目标基础信息。
2. 全面扫描(全端口 + 深度探测)
sudo nmap -p- -sS -sV -O -A --script=vuln 38.100.193.70
-p-:扫描 1-65535 所有端口。--script=vuln:运行漏洞检测脚本(如http-vuln*,smb-vuln*)。- 耗时:较长(约 30-60 分钟),但信息全面。
3. 隐蔽扫描(避免触发告警)
sudo nmap -T2 -sS -Pn --scan-delay 1s --randomize-hosts 38.100.193.70
-T2:慢速模式(降低流量特征)。-Pn:跳过主机发现(假设目标在线)。--scan-delay 1s:每个包间隔 1 秒。--randomize-hosts:随机扫描顺序。- 用途:规避基础 IDS/防火墙检测。
4. UDP 关键服务扫描
sudo nmap -sU -p 53,67,68,123,161,162 38.100.193.70
- 扫描 DNS(53)、DHCP(67/68)、NTP(123)、SNMP(161/162)等关键 UDP 服务。
- 优化:避免全端口 UDP 扫描(耗时过长)。
5. Web 专项扫描
sudo nmap -p 80,443,8080 --script=http-title,http-enum,http-shellshock 38.100.193.70
- 探测 HTTP 服务标题、目录枚举、Shellshock 漏洞。
- 可结合
gobuster或nikto进行深度扫描。
6. 防火墙绕过扫描
sudo nmap -f --mtu 24 -D RND:10 -g 53 --proxies socks4://proxy_ip:1080 38.100.193.70
-f:分片数据包。-D RND:10:添加 10 个随机诱饵 IP。-g 53:伪装源端口为 DNS(53)。--proxies:通过代理扫描。- 用途:绕过防火墙/IP 封禁。
Nmap 常用技巧
保存输出:
nmap -oN report.txt -oX report.xml 38.100.193.70 # 文本/XML 格式 nmap -oG - 38.100.193.70 | grep "open" # 提取开放端口对比扫描结果:
ndiff scan1.xml scan2.xml # 检测目标变化搜索 NSE 脚本:
ls /usr/share/nmap/scripts/*http* # 查找 HTTP 相关脚本 nmap --script-help=http-vuln* # 查看脚本帮助
推荐进阶组合命令
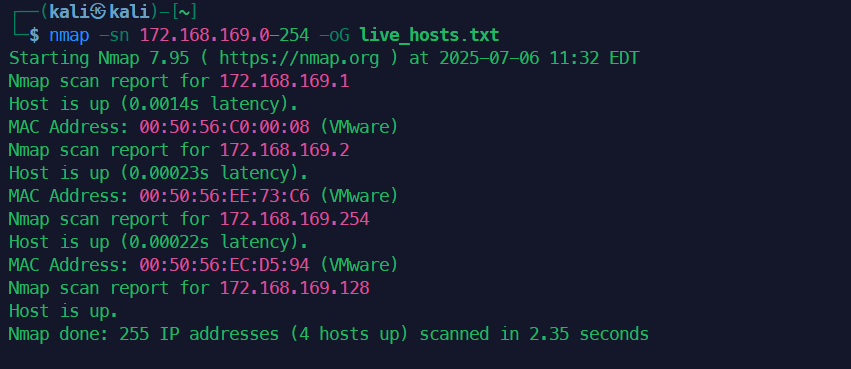
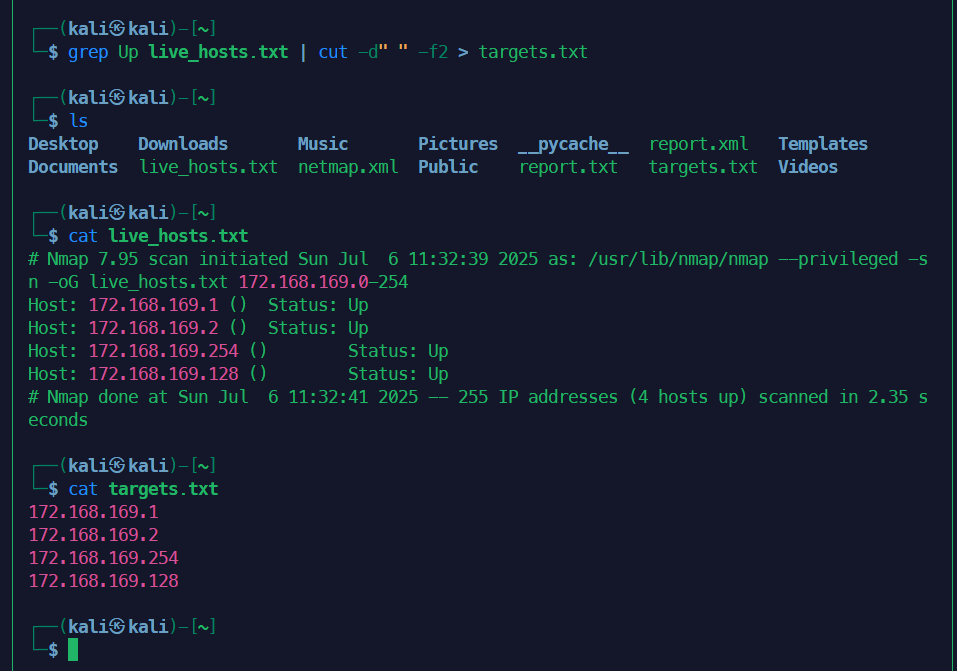
1. 高效主机发现 + 服务扫描
# 先快速发现存活主机
nmap -sn 38.100.193.70-254 -oG live_hosts.txt
# 提取IP后扫描TOP100端口
grep Up live_hosts.txt | cut -d" " -f2 > targets.txt
nmap -sT -A --top-ports 100 -iL targets.txt -oA full_scan
2. 隐蔽式主机发现(避开防火墙)
nmap -Pn -sn --disable-arp-ping --packet-trace \
--scan-delay 2s 38.100.193.0/24
-Pn:跳过主机发现(假设所有主机在线)--disable-arp-ping:禁用ARP探测--packet-trace:显示发送的数据包
3. 关键服务快速定位
nmap -p21,22,80,443,3389 -sT --open 38.100.193.70-254 -oG key_services.txt
--open:仅显示开放端口- 目标端口:FTP/SSH/Web/RDP等核心服务
实用技巧
# 1. 将扫描结果导入Metasploit
cat top-port-sweep.txt | awk '/Up/{print $2}' > hosts.txt
msfconsole -qx "db_import hosts.txt; services"
# 2. 生成拓扑图(需Nmap编译图形支持)
nmap -sn --traceroute --packet-trace 38.100.193.0/24 -oX netmap.xml
xsltproc netmap.xml -o topology.html
Masscan快速网络扫描
为扫描整个互联网而设计,六分钟扫描整个互联网,每秒发送一千万个包,masscan实现了自定义的tcp/ip栈堆需要使用sudo权限。
sudo apt install masscan
sudo masscan -p80 192.168.1.0/8
sudo macscan -p80 192.168.1.0/24 --rate=1000 -e tap0 --router -ip 192.168.1.1
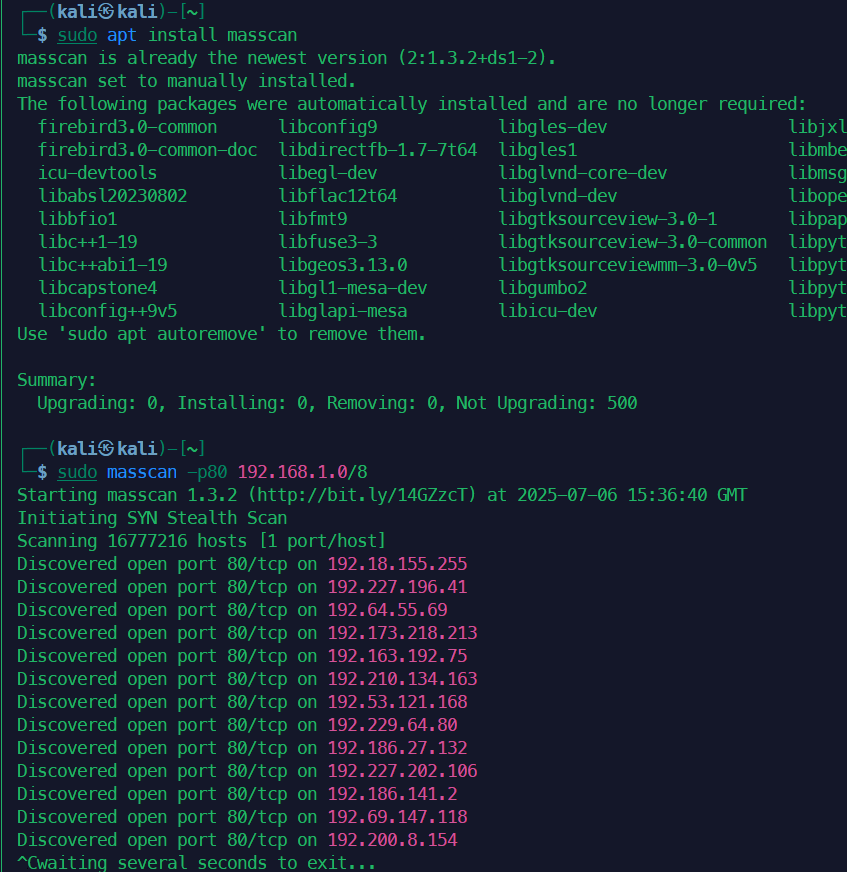
命令解析
1. sudo masscan -p80 192.168.1.0/8
作用:对超大型网络进行快速端口扫描
关键参数:
-p80:只扫描80端口(HTTP服务)192.168.1.0/8:扫描整个B类私有网络(192.0.0.0-192.255.255.255),包含 1677万台主机
执行流程:
- 不进行主机发现,直接扫描目标端口
- 通过SYN扫描发送TCP SYN包到目标80端口
- 收到SYN/ACK响应则标记为开放
风险:
- 扫描范围过大可能导致网络拥塞
可能触发大规模安全告警
2. sudo masscan -p80 192.168.1.0/24 --rate=1000 -e tap0 --router-ip 192.168.1.1
作用:对特定子网进行精确控制的扫描
修正:应为
masscan(非macscan)关键参数:
-p80:扫描80端口192.168.1.0/24:扫描C类子网(254个主机)--rate=1000:限速1000包/秒-e tap0:使用特定虚拟网络接口--router-ip 192.168.1.1:指定网关IP用于ARP解析
执行流程:
- 向网关192.168.1.1发送ARP请求
- 获取目标主机MAC地址
- 通过tap0接口发送定制SYN包
- 严格按1000包/秒速率扫描
Masscan 核心优势
| 特性 | Masscan | Nmap |
|---|---|---|
| 扫描速度 | 100万包/秒 | 数千包/秒 |
| 大型网络处理 | 内置分片处理 | 需要手动分割 |
| 资源消耗 | 低内存占用 | 较高内存占用 |
| 扫描精度 | 端口状态检测 | 完整协议栈交互 |
| 隐蔽性 | 无状态扫描 | 有状态检测 |
Masscan 实用用法示例
1. 基础扫描
# 扫描单个IP的TOP100端口
sudo masscan 203.0.113.1 -p0-65535 --top-ports 100
# 扫描网段的多端口(HTTP/HTTPS)
sudo masscan 192.168.1.0/24 -p80,443,8000-8100
2. 精准速率控制
# 限制扫描速率(避免触发防火墙)
sudo masscan 10.0.0.0/16 -p22 --rate=500 # 500包/秒
# 随机化扫描顺序
sudo masscan 192.168.0.0/24 -p80 --randomize-hosts
3. 大型网络扫描优化
# 分布式扫描(多文件分片)
sudo masscan 172.16.0.0/12 -p443 --shard 1/10 # 第1/10片段
sudo masscan 172.16.0.0/12 -p443 --shard 2/10 # 第2/10片段
# 保存/恢复扫描进度
sudo masscan -p80 10.0.0.0/8 -oJ scan.json --resume paused.conf
4. 结果输出与处理
# XML格式输出(兼容Nmap工具)
sudo masscan 192.168.1.0/24 -p1-100 -oX scan.xml
# 提取开放端口IP
sudo masscan -p443 203.0.113.0/24 -oG - | grep 'open' | awk '{print $4}'
# 生成可视化报告
masscan -p80 192.168.1.0/24 -oX scan.xml
nmap-parse-output scan.xml html > report.html
5. 绕过防火墙技巧
# 伪装源端口(使用53端口发送)
sudo masscan -p80 203.0.113.0/24 --source-port 53
# 使用代理链扫描
proxychains masscan -p443 198.51.100.0/24
# 分片数据包
sudo masscan -p22 192.168.1.0/24 --mtu 512
使用场景对比
| 场景 | 推荐命令 |
|---|---|
| 快速资产发现 | masscan -p80,443 10.0.0.0/8 --rate=10000 |
| 精确服务扫描 | nmap -sV -O 192.168.1.1-100 |
| 超大型网络端口普查 | masscan 203.0.113.0/24 --shard 1/50 |
| 内网隐蔽扫描 | nmap -T2 -sS -Pn --scan-delay 500ms |
注意事项
- 法律合规:扫描前必须获得明确授权
- 带宽控制:使用
--rate参数避免网络瘫痪 - 结果验证:Masscan结果需用Nmap二次验证
- 持久扫描:大型网络使用
--resume保存进度 - 更新数据库:定期
apt update && apt upgrade masscan获取最新指纹库
🔔 想要获取更多网络安全与编程技术干货?
关注 泷羽Sec-静安 公众号,与你一起探索前沿技术,分享实用的学习资源与工具。我们专注于深入分析,拒绝浮躁,只做最实用的技术分享!💻
扫描下方二维码,马上加入我们,共同成长!🌟
👉 长按或扫描二维码关注公众号
或者直接回复文章中的关键词,获取更多技术资料与书单推荐!📚

