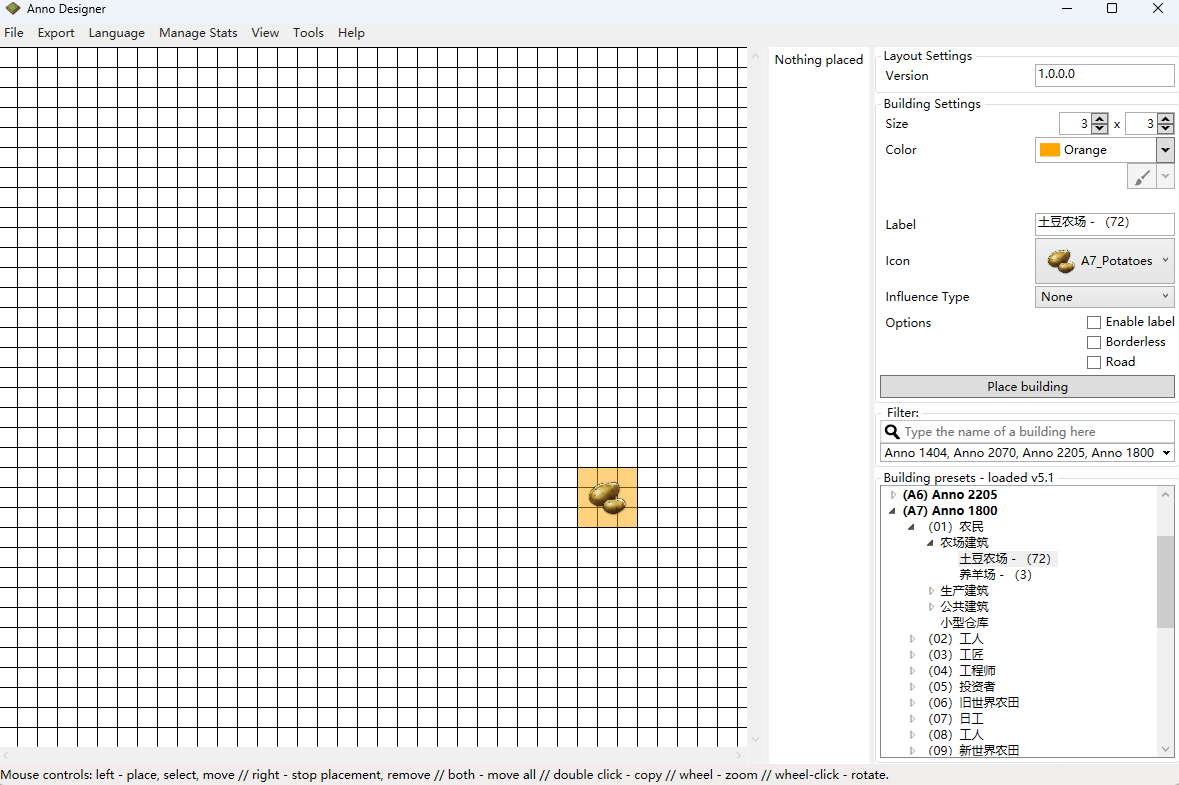
最近沉迷玩纪元1800,当总督各种规划城市,用到一个布局设计软件AnnoDesigner,可惜没有汉化看起来比较难受,所以尝试汉化翻译一下。汉化文件在文末,懒得看我啰嗦的直接跳文末下载替换就行。
找到语言相关配置文件
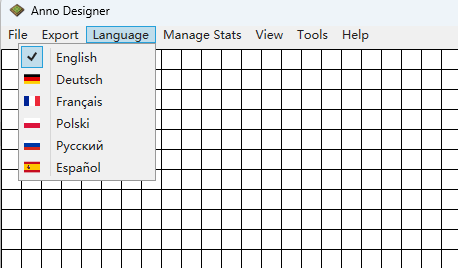
这个软件一开始只有这几个语言选项,没有中文
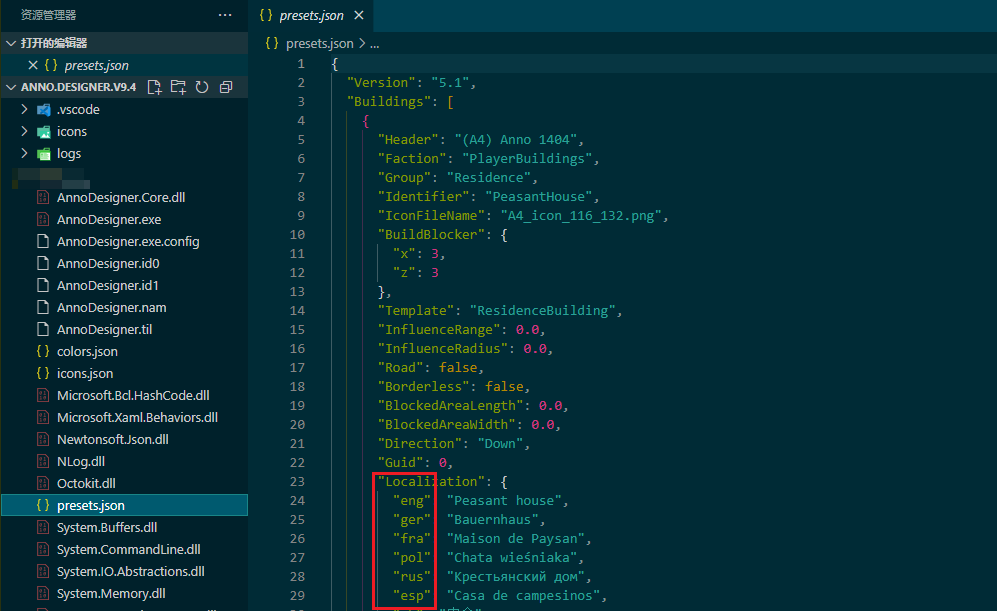
从release下载的文件夹中发现json文件,疑似是语言的配置文件。
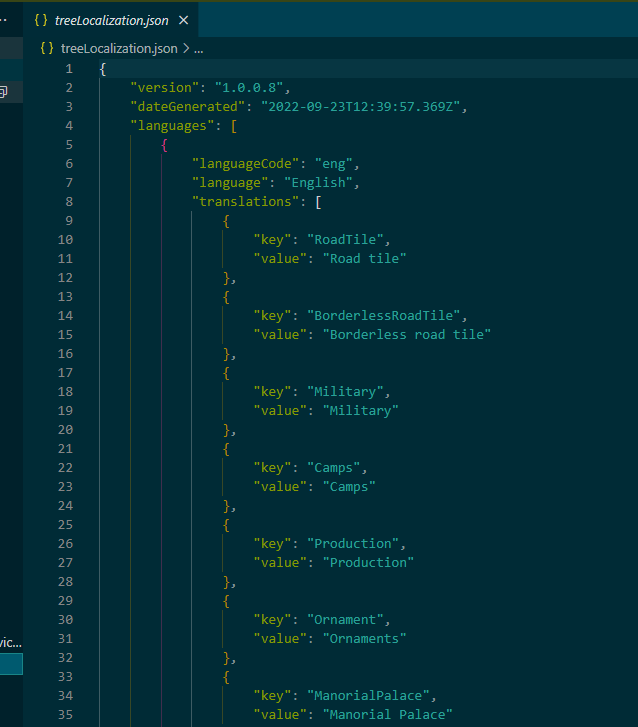
提取并翻译
用AI写了个脚本
1import json
2import pandas as pd
3
4# 读取JSON文件
5with open('presets.json', 'r', encoding='utf-8') as f:
6 data = json.load(f)
7
8# 准备存储提取的数据
9extracted_data = []
10
11# 遍历所有建筑
12for building in data['Buildings']:
13 if 'Localization' in building and building['Localization'].get('eng'):
14 item = {
15 'Header': building.get('Header', ''),
16 'Faction': building.get('Faction', ''),
17 'Group': building.get('Group', ''),
18 'Identifier': building.get('Identifier', ''),
19 'IconFileName': building.get('IconFileName', ''),
20 'English_Name': building['Localization'].get('eng', '')
21 }
22 extracted_data.append(item)
23
24# 创建DataFrame并保存为CSV
25df = pd.DataFrame(extracted_data)
26df.to_csv('building_icons.csv', index=False, encoding='utf-8-sig')
27
28# 打印预览
29print("已提取数据并保存到 building_icons.csv")
30print("\n数据预览:")
31print(df.head())
这是提取另一个文件的
1import json
2import csv
3
4def extract_english_translations():
5 # 读取翻译文件
6 with open('treeLocalization.json', 'r', encoding='utf-8') as f:
7 data = json.load(f)
8
9 # 查找英文语言部分
10 translations = []
11 for lang in data['languages']:
12 if lang['languageCode'] == 'eng':
13 translations = lang['translations']
14 break
15
16 # 保存为CSV格式
17 with open('english_translations.csv', 'w', encoding='utf-8', newline='') as f:
18 writer = csv.writer(f)
19 # 写入表头
20 writer.writerow(['Key', 'English'])
21 # 写入翻译数据
22 for item in translations:
23 writer.writerow([item['key'], item['value']])
24
25 print(f'提取了 {len(translations)} 个英文翻译到 english_translations.csv')
26 return translations
27
28if __name__ == '__main__':
29 extract_english_translations()
尝试替换
一开始还尝试用AI翻译,后来实在是太多了,AI老是思考耽误时间,最后还是充了个有道会员翻译了一下,非常快速。
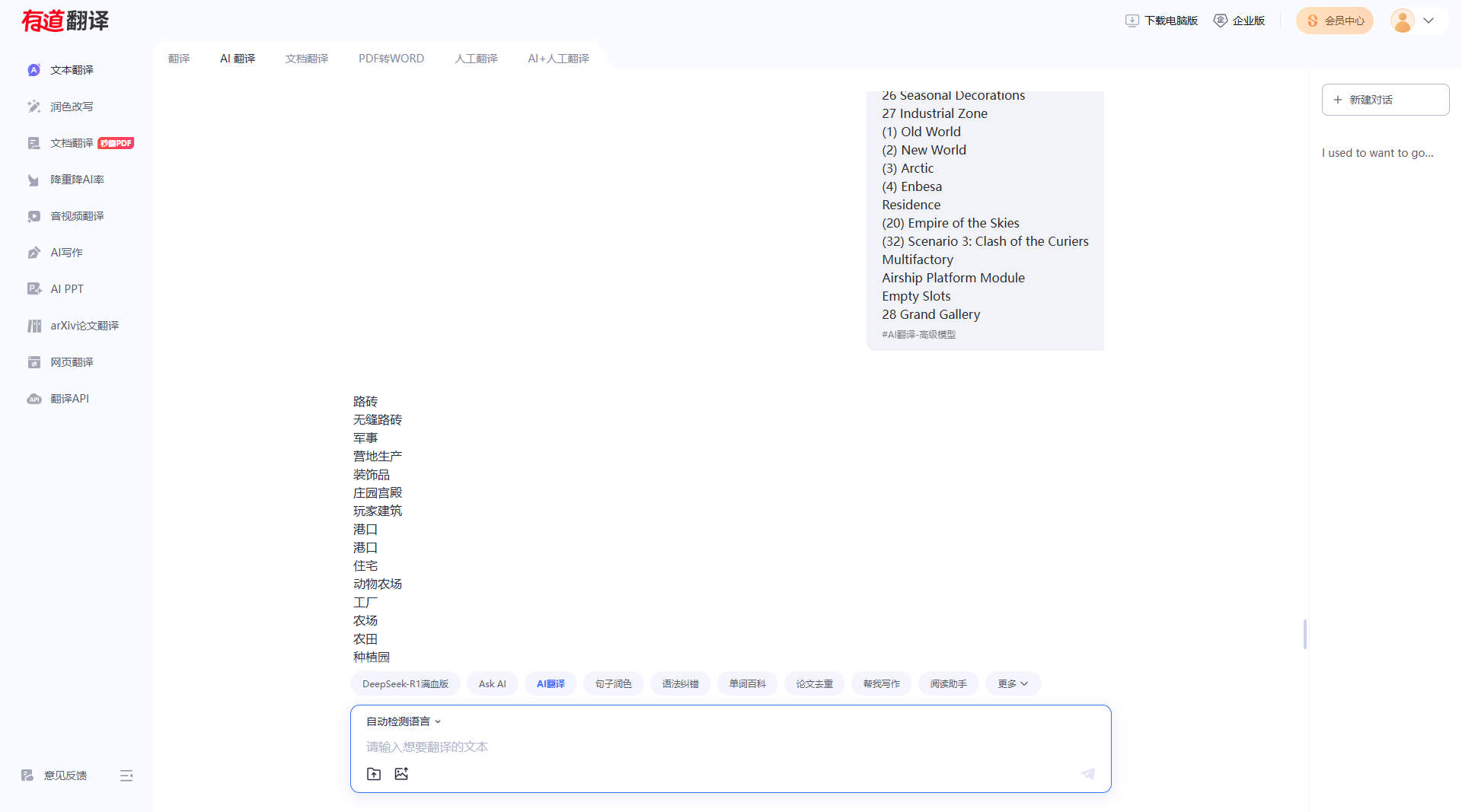
用WPS表格打开csv文件比较好直接粘贴,粘贴后检查表格翻译是否对应,因为我只玩了1800,但是这个软件还包括其他的几个系列,所以我也不确定翻译是否正确,总之先用着机翻的吧。WPS保存后记得用VScode打开,重新用编码GB2312打开,再改为用UTF-8保存。
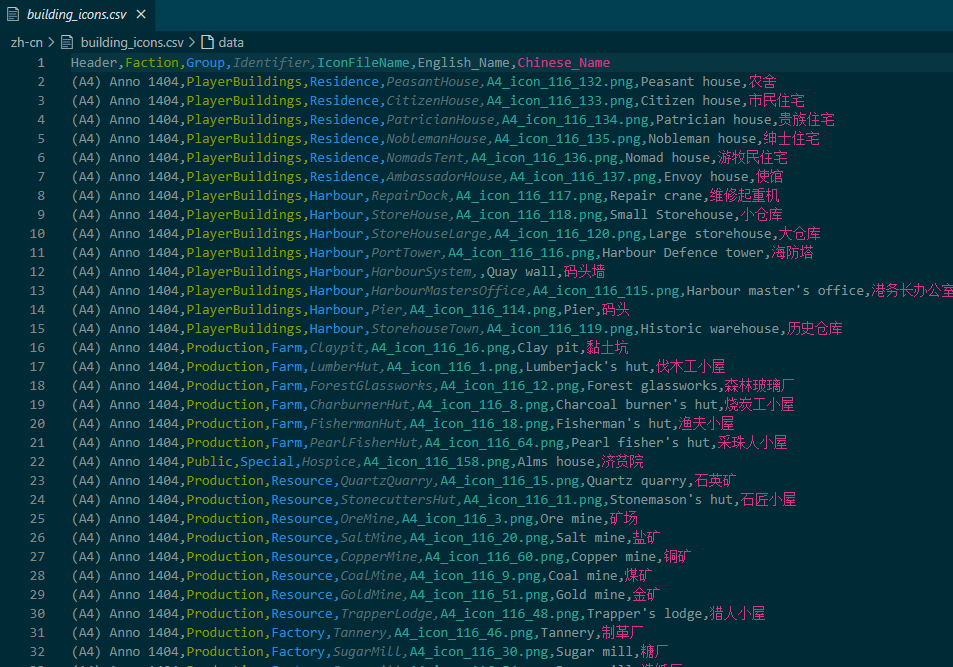
然后又用AI写两个脚本,把汉化的内容模仿原来的json文件的形式补充回去。
1import json
2import pandas as pd
3
4def update_presets():
5 # 读取建筑翻译映射
6 df = pd.read_csv('building_icons.csv')
7 translations = dict(zip(df['English_Name'], df['Chinese_Name']))
8
9 # 读取 presets.json
10 with open('presets.json', 'r', encoding='utf-8') as f:
11 data = json.load(f)
12
13 # 遍历并更新每个建筑的本地化
14 updated = 0
15 for building in data['Buildings']:
16 if 'Localization' in building:
17 # 根据英文名查找中文翻译
18 eng_name = building['Localization'].get('eng')
19 if eng_name and eng_name in translations:
20 # 添加中文翻译
21 building['Localization']['zh'] = translations[eng_name]
22 updated += 1
23
24 # 保存更新后的文件
25 with open('presets.json', 'w', encoding='utf-8') as f:
26 json.dump(data, f, ensure_ascii=False, indent=2)
27
28 print(f"Successfully updated {updated} Chinese names in presets.json")
29
30if __name__ == "__main__":
31 try:
32 update_presets()
33 except Exception as e:
34 print(f"Error saving file: {str(e)}")
1import json
2import pandas as pd
3
4def create_chinese_translations():
5 # 读取CSV文件
6 df = pd.read_csv('english_translations.csv')
7
8 # 创建中文翻译数据结构
9 chinese_lang = {
10 "languageCode": "zh",
11 "language": "简体中文",
12 "translations": []
13 }
14
15 # 遍历CSV中的每一行,生成翻译条目
16 for _, row in df.iterrows():
17 if pd.notna(row['Chinese']): # 只添加有中文翻译的条目
18 translation = {
19 "key": row['Key'],
20 "value": row['Chinese']
21 }
22 chinese_lang['translations'].append(translation)
23
24 # 读取原始treeLocalization.json
25 with open('treeLocalization.json', 'r', encoding='utf-8') as f:
26 tree_data = json.load(f)
27
28 # 添加中文语言到languages列表
29 tree_data['languages'].append(chinese_lang)
30
31 # 保存更新后的文件
32 with open('treeLocalization.json', 'w', encoding='utf-8') as f:
33 json.dump(tree_data, f, ensure_ascii=False, indent=4)
34
35 print(f'已添加 {len(chinese_lang["translations"])} 条中文翻译')
36
37if __name__ == '__main__':
38 create_chinese_translations()
发现语言选项已经编译到exe中
翻译好后打开发现还是没有中文选项,找了一下软件配置文件,似乎语言选择的键值没有写再配置文件中,那应该就是直接编码在exe中了。
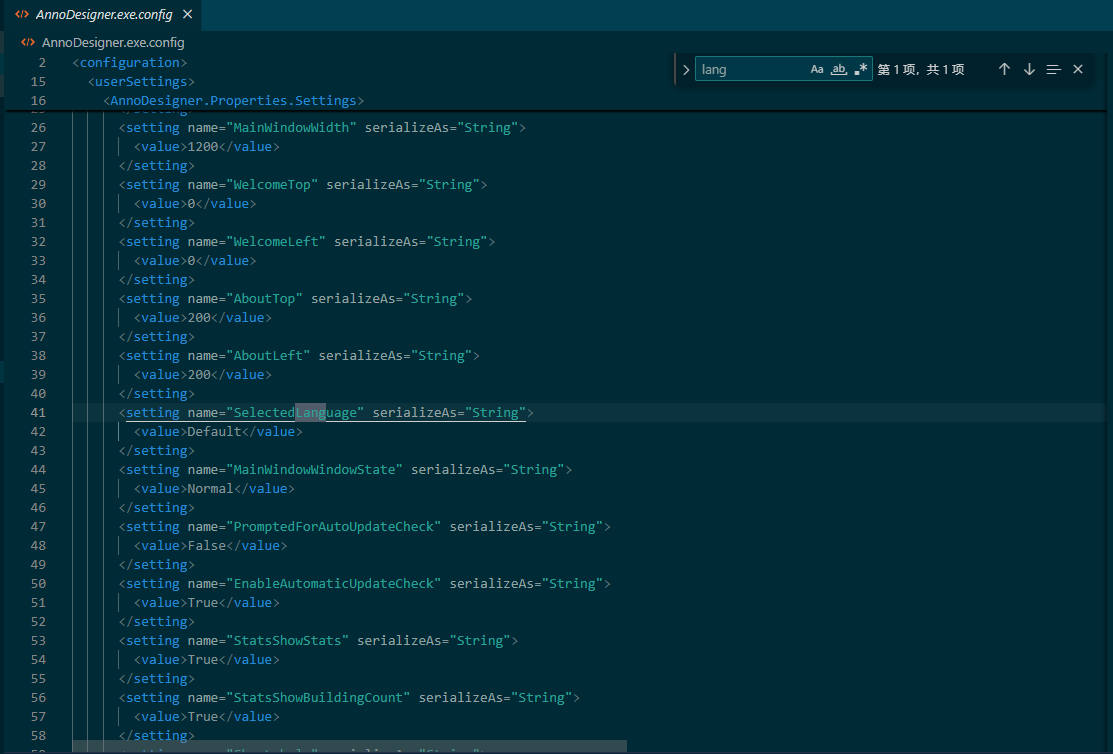
用IDA打开查了一下确实。
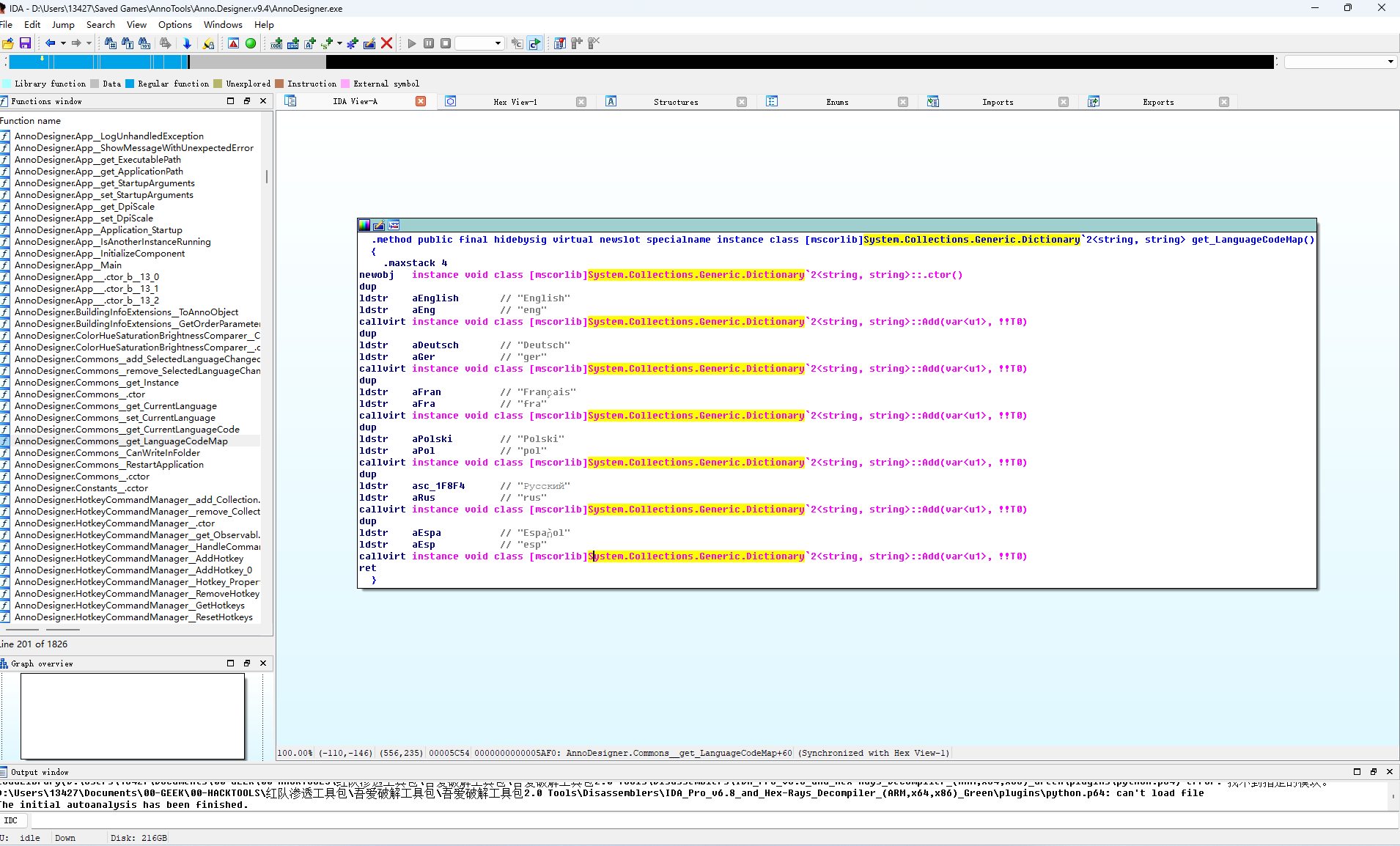
翻了一下作者的源码,发现git仓库是有sln文件的,顺利的话clone下来,补充中文的语言选择选项,重新编译一下就行。
安装一下编译必要的组件
找到语言选项
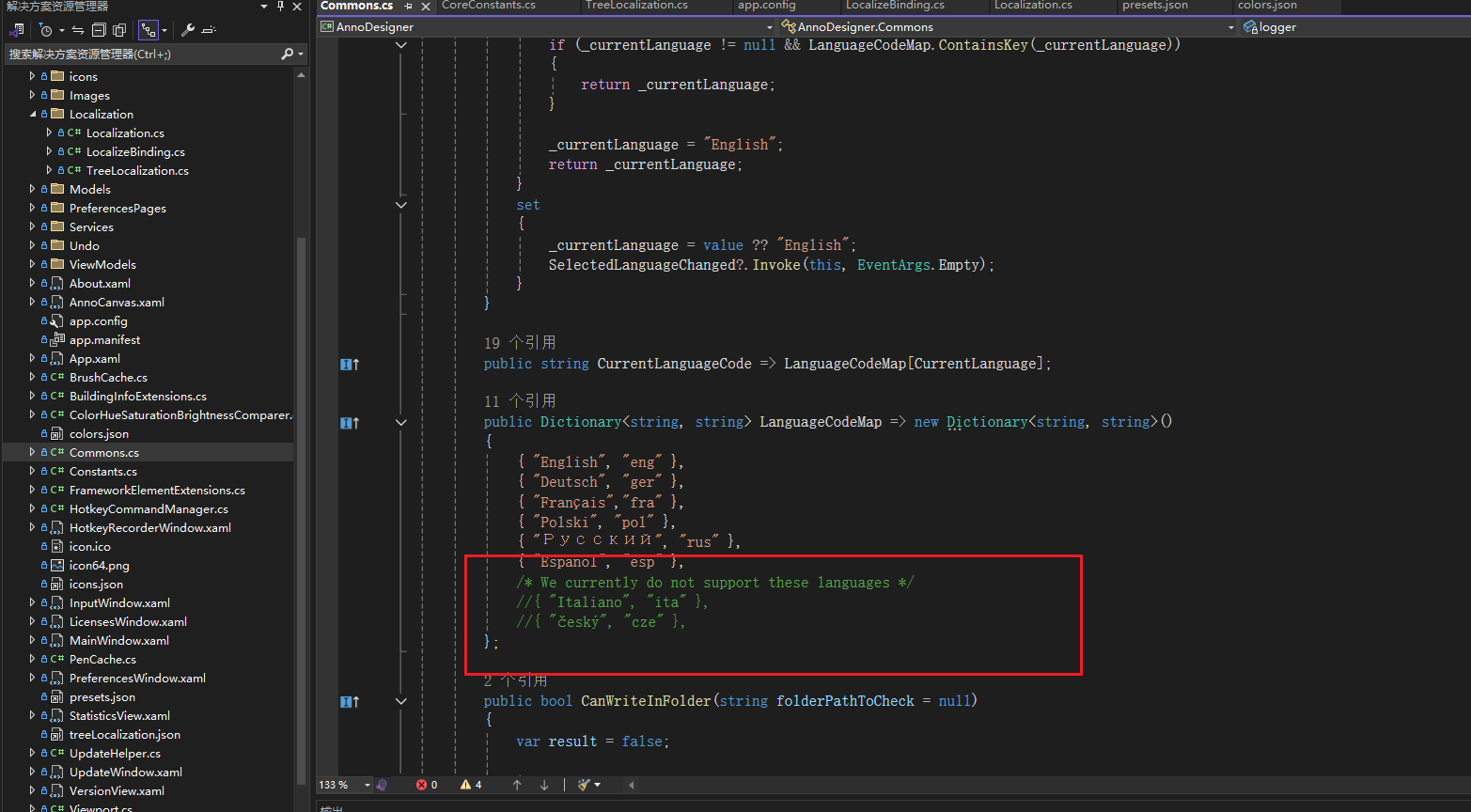
添加中文选项
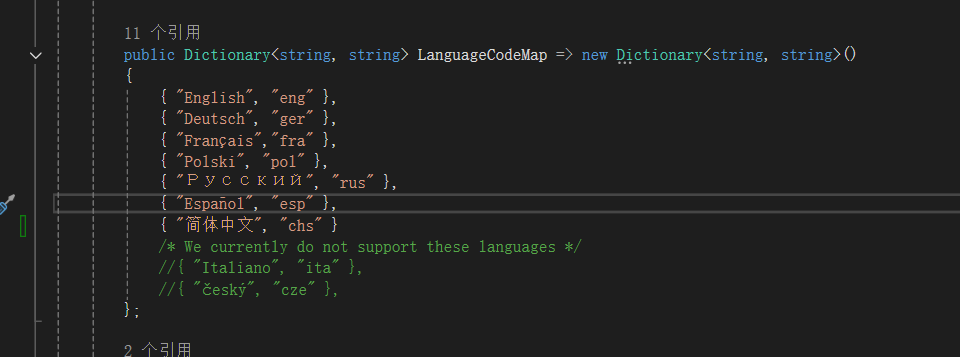
把中文的code改统一,按照作者这个语言文件风格的code方式应该是chs。
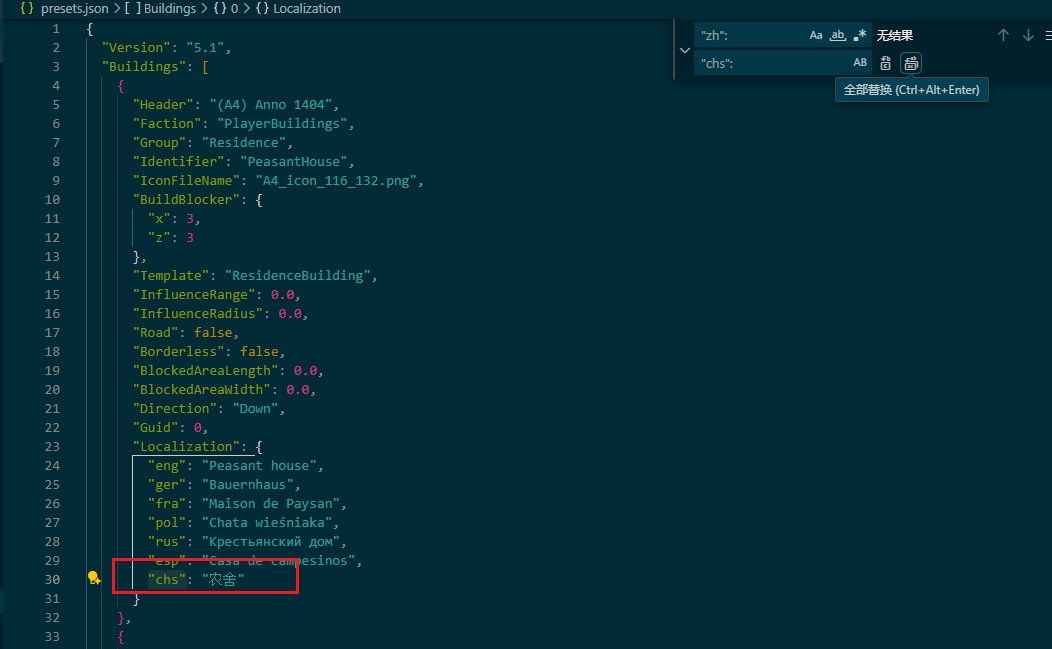
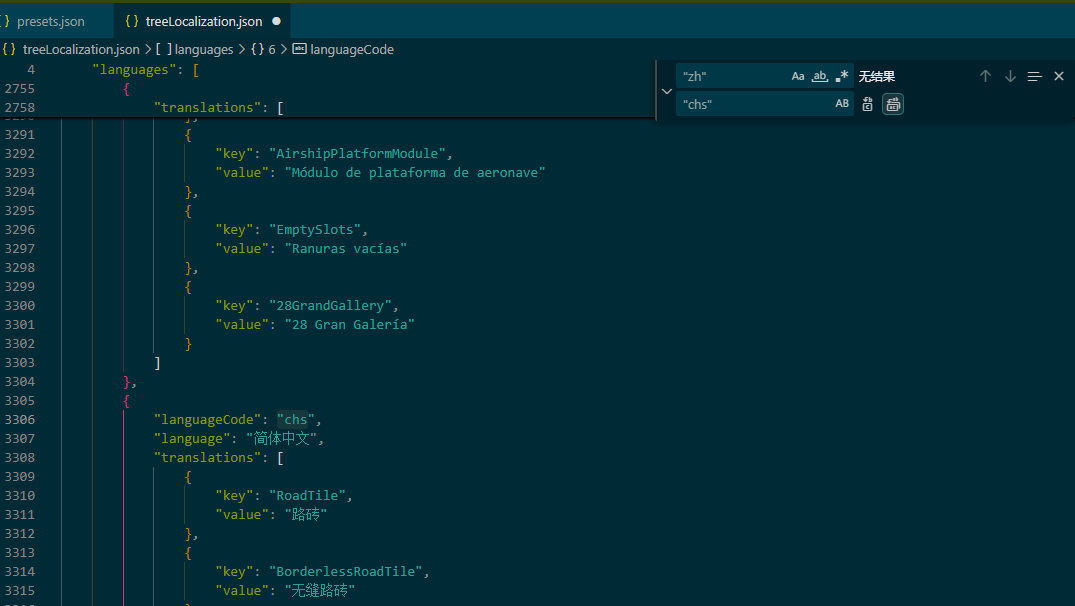
翻到了界面语言的翻译选项,顺手翻译一下
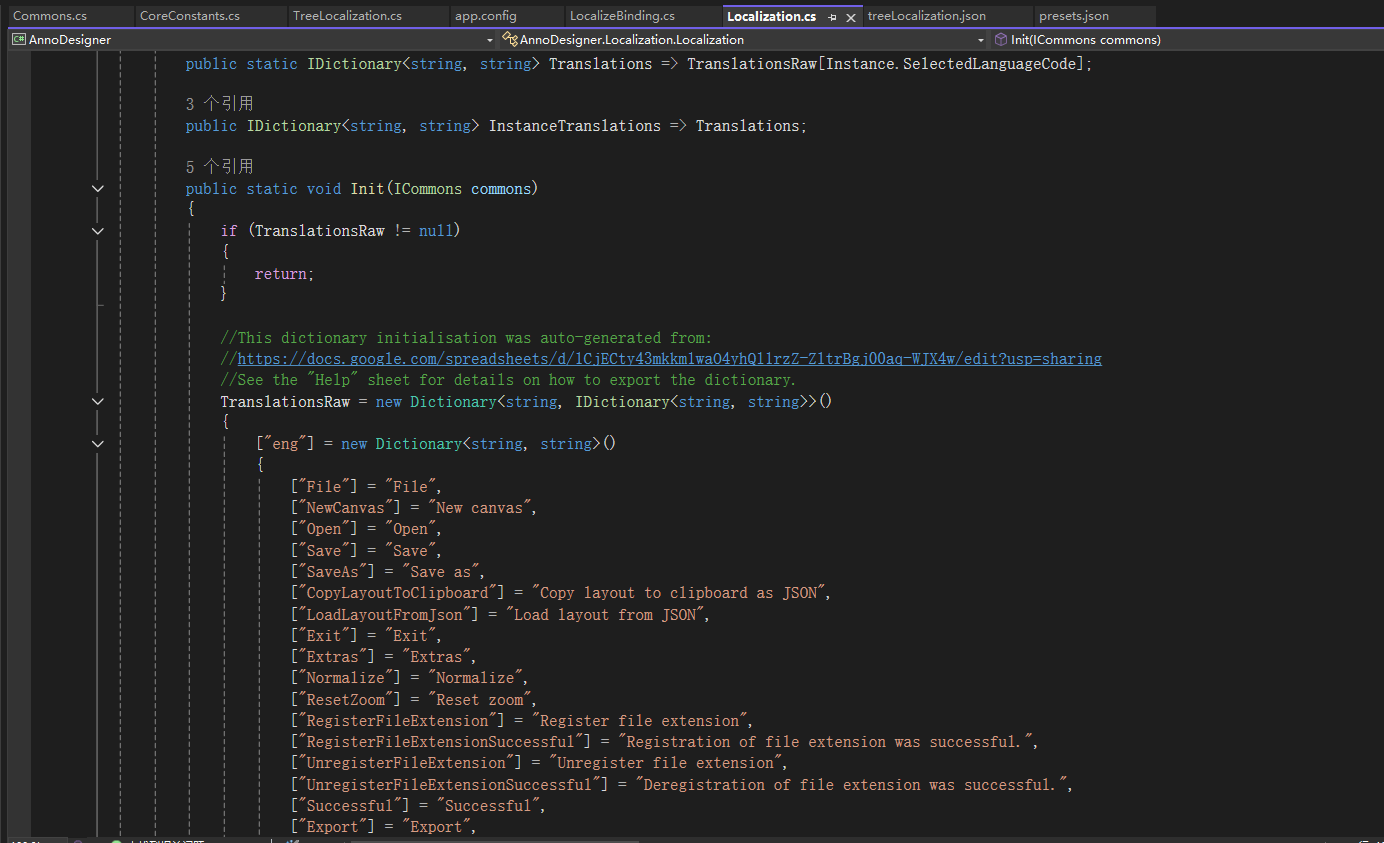
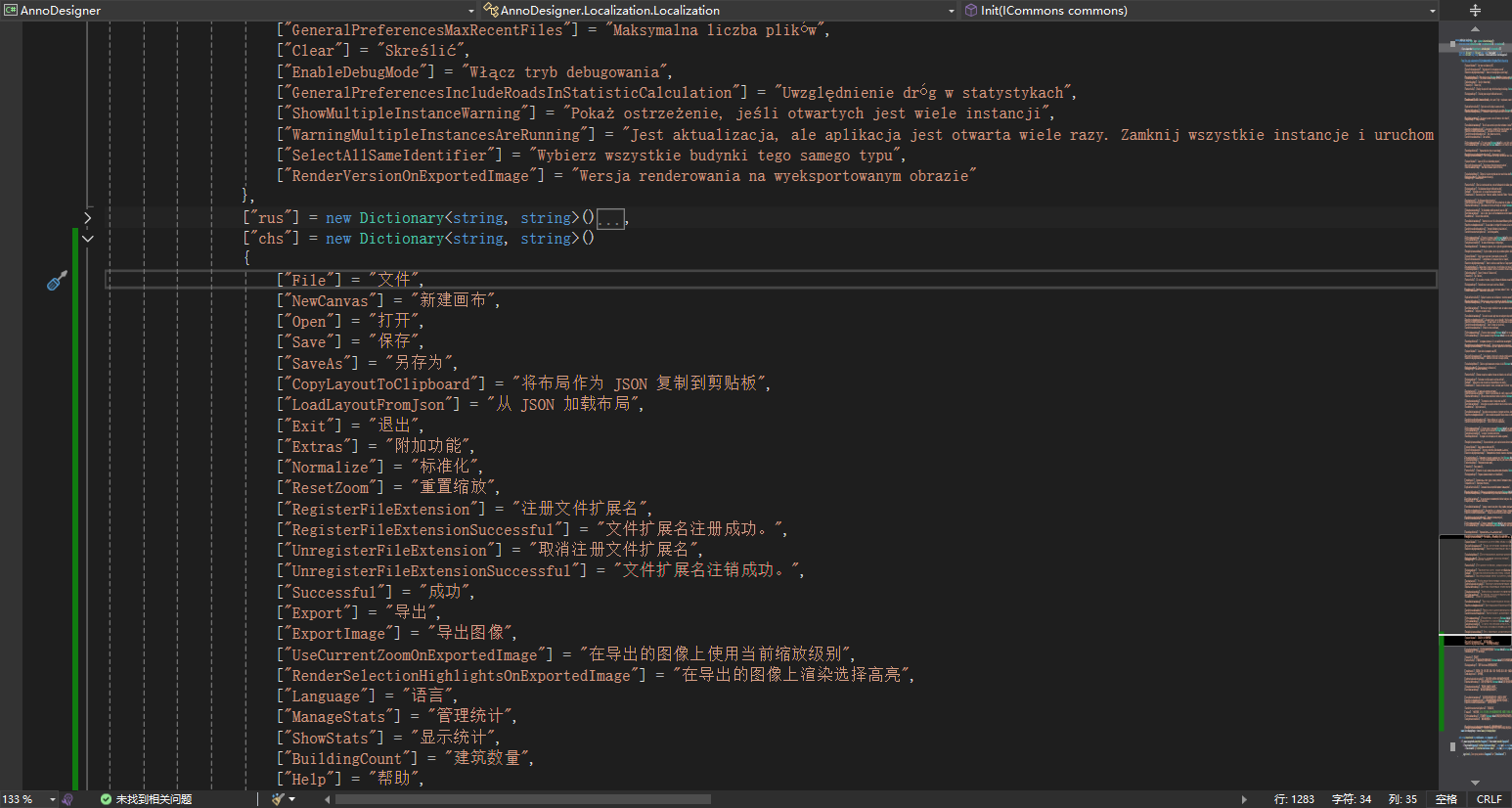
但是重新编译发现失败了
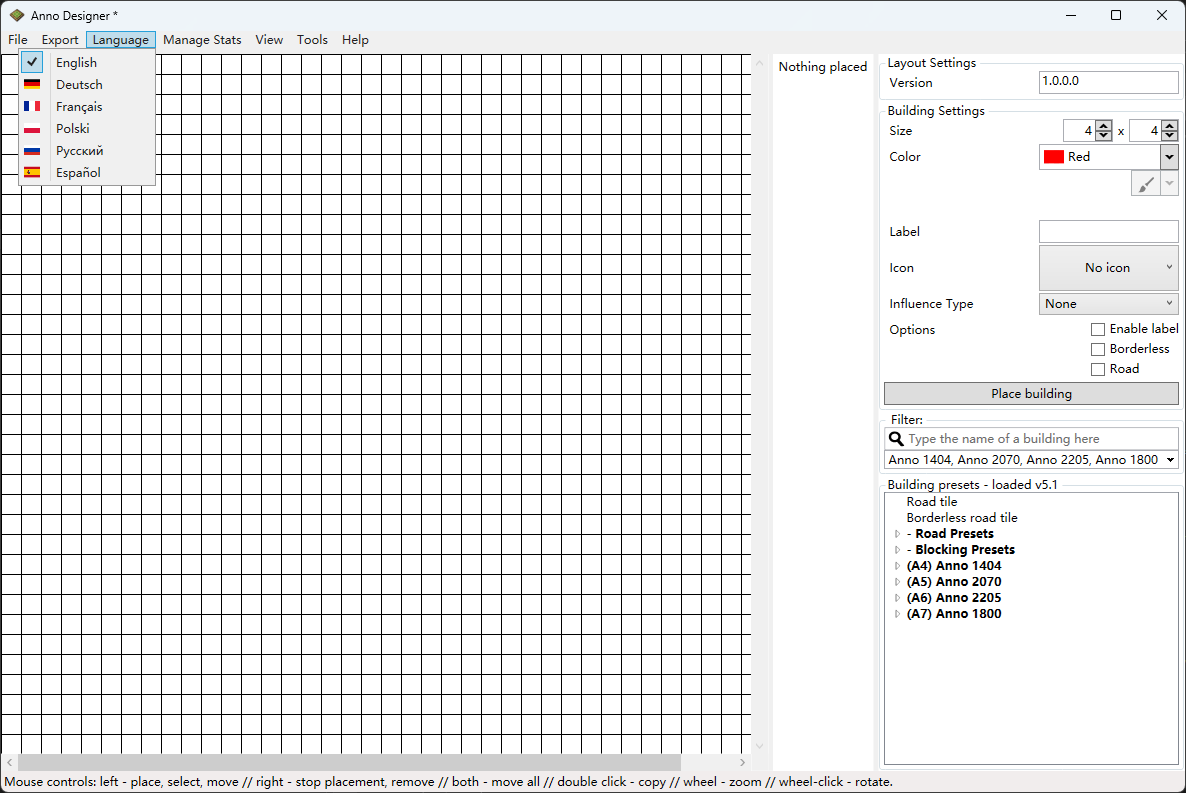
在代码里看到作者给的一个连接
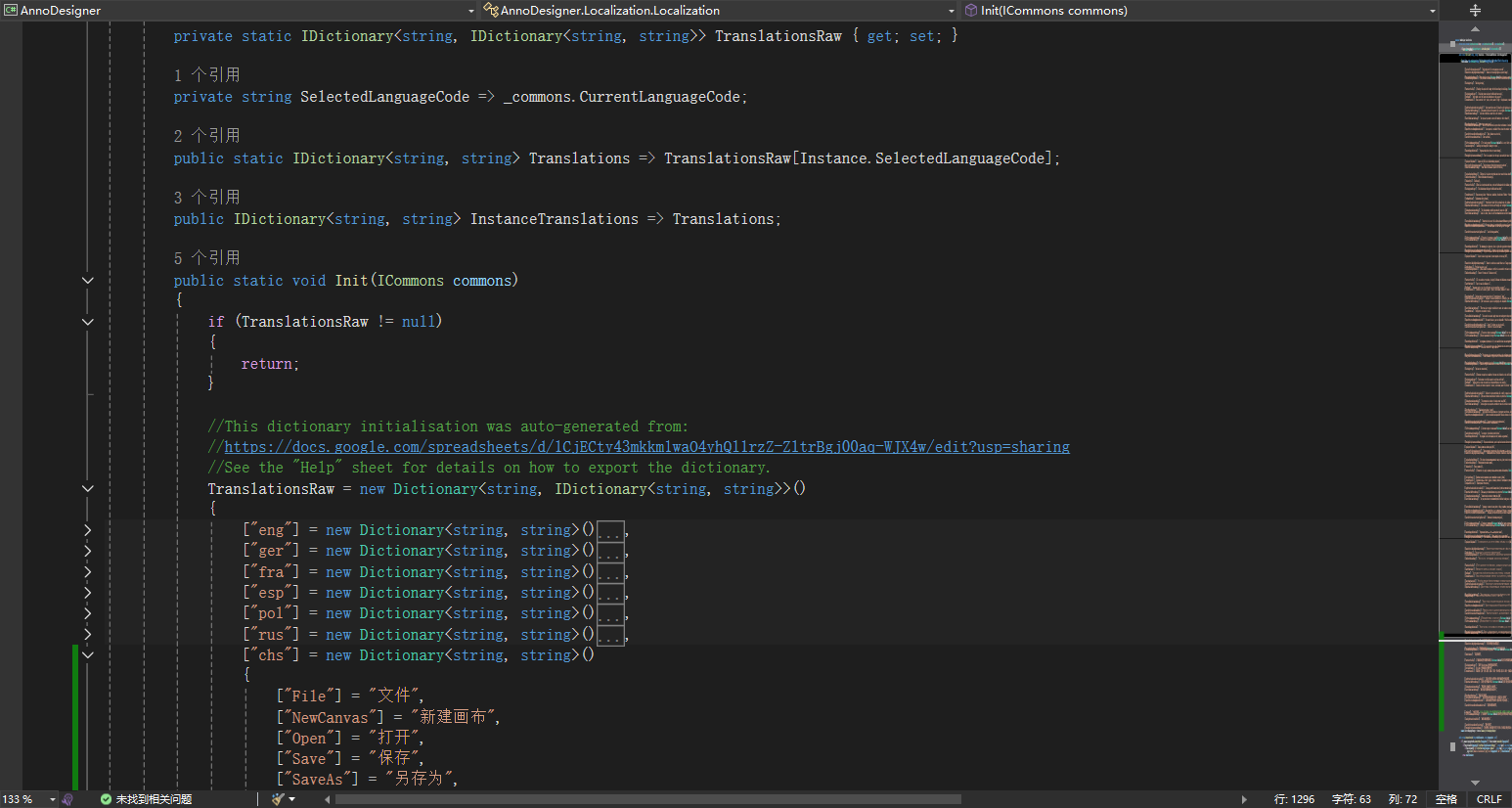
好像已经有人贡献过中文翻译了,但是为什么不合并呢,怎么不发布中文版呢?
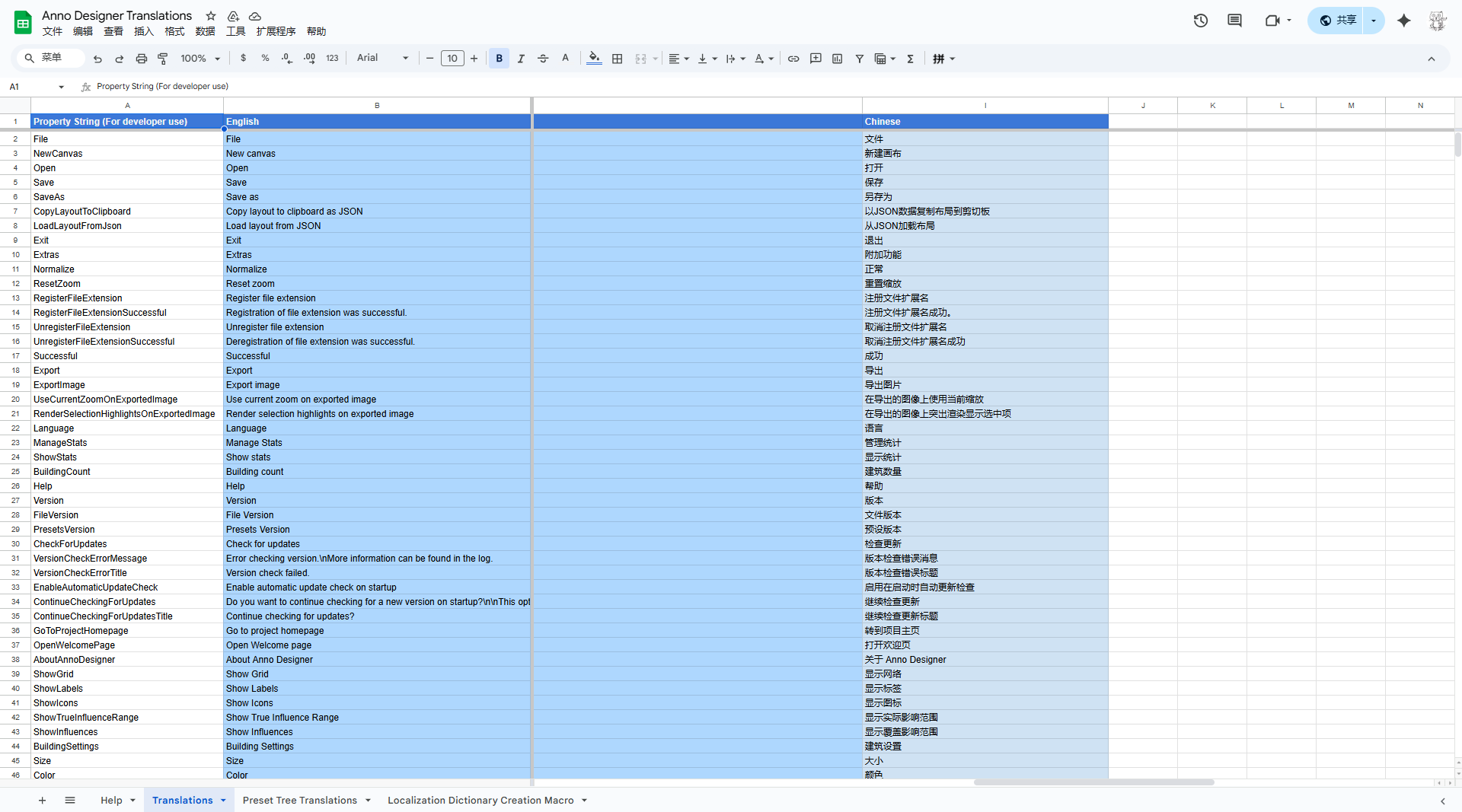
最后看到一段生成语言code的代码,但是我在源码里面没找到再哪里改,这也许是失败的原因。
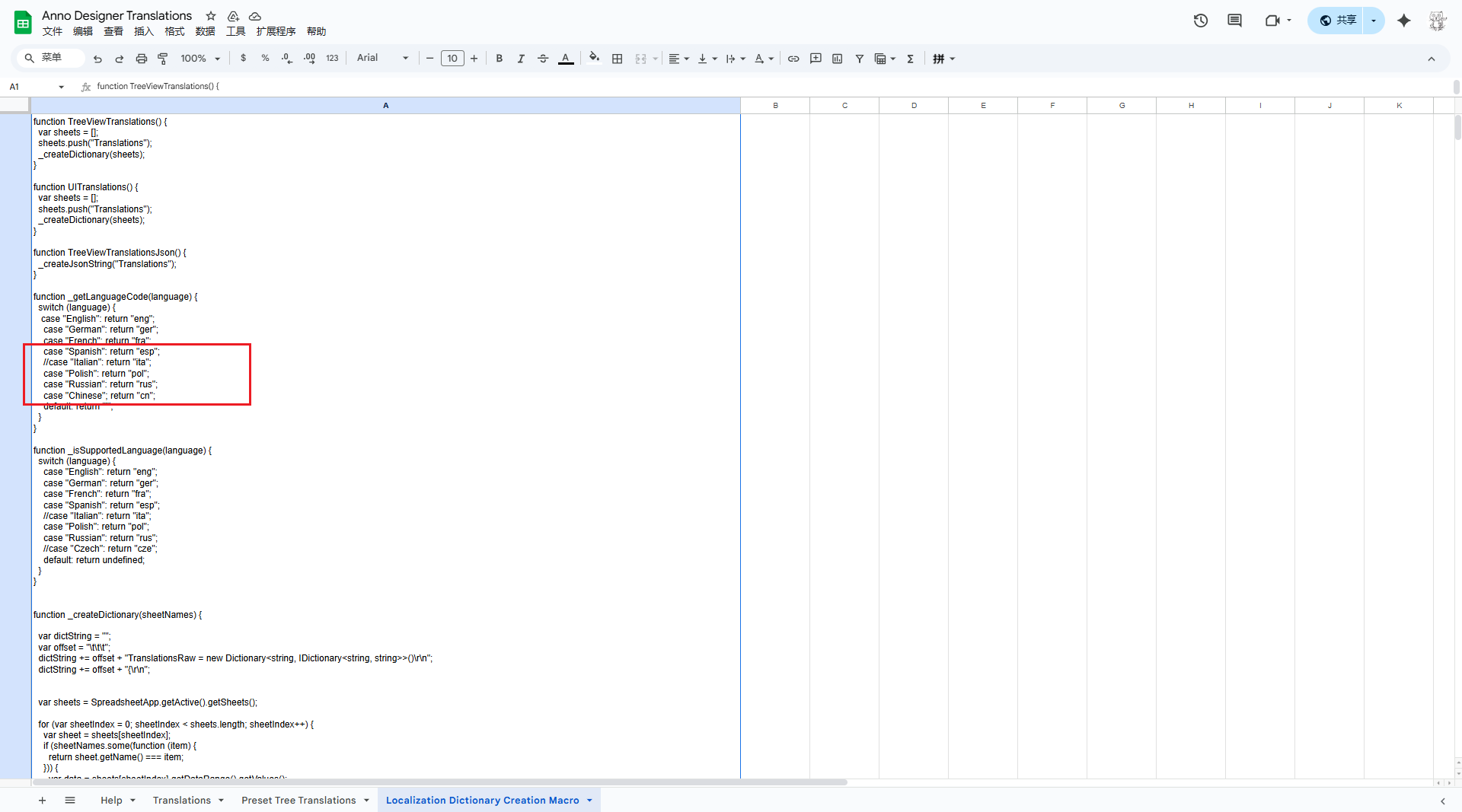
英文变eeng,中文变英文
编译失败没事,还有一招头天换日。
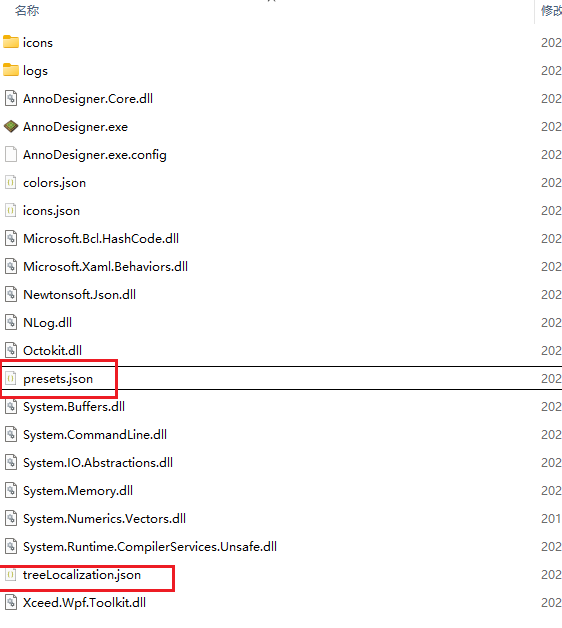
最后分享一下我机翻的语言替换文件,下载好后直接丢文件夹下替换就行。只简单校对了一下机翻的内容,保证Anno1800的翻译基本能看,如果有错误的自行用记事本之类的软件打开json文件搜索修改就可。其他几个纪元的系列还没玩过,不知道机翻的含义对不对,如果不对就自己改一下吧,也欢迎在评论区分享你的汉化文件。
我用夸克网盘给你分享了「AnnoDesigner汉化」,点击链接或复制整段内容,打开「夸克APP」即可获取。
筷莱旻潆鱪麯麺夺郝
/~e25c38IeIg~:/
链接:https://pan.quark.cn/s/e8385005d590
这是我用软件画的住宅布局,我觉得用起来还不错


