关注泷羽Sec和泷羽Sec-静安公众号,这里会定期更新与 OSCP、渗透测试等相关的最新文章,帮助你理解网络安全领域的最新动态。
01 数据安全
4、数据存储1
- 题目名称: 数据存储1
- 分值: 100分
- 描述: 工程师小王开发了对数据处理的程序,分析程序功能,解密文件获取原始数据,提交第6行第2列数据。
文件分析
1. 附件内容
1$ unzip re87a57766.zip
2Archive: re87a57766.zip
3 Length Date Time Name
4--------- ---------- ----- ----
5 3296 2025-12-02 05:20 info_19ff9a2.ori.en
6 14552 2025-12-02 05:19 re87a57766
2. 文件类型
1$ file re87a57766
2re87a57766: ELF 64-bit LSB executable, x86-64, version 1 (SYSV),
3 dynamically linked, stripped
4
5$ file info_19ff9a2.ori.en
6info_19ff9a2.ori.en: ASCII text, with CRLF line terminators
程序分析
1. 字符串分析
1$ strings re87a57766 | grep -E "(info|base64|ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789)"
2
3ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/
4./info_19ff9a2.ori
5info_19ff9a2.ori.en
关键发现:
- 程序使用 Base64 字符表
- 输入文件:
./info_19ff9a2.ori - 输出文件:
info_19ff9a2.ori.en
2. 加密逻辑推断
根据程序字符串和文件名:
.ori→ 原始文件(Original).ori.en→ 加密文件(Encrypted)- 使用 Base64 编码进行"加密"
解密过程
1. 查看加密文件
1$ head -3 info_19ff9a2.ori.en
2MjY1MjMxNDY5NDEgNzA2MTYzMTk2MDIxMTU1NzIyIGE5ZWFjNzNAMWQzLmNuCg==
3MjY2MjEzODU2NTUgODg1ODgyMTk4ODMwMjU3MTgzIDE4Y2E3ZWU5QDI2MC5jb20uY24K
4MzU2MTk4ODY0NzQgNzQ3ODUyMTk3NTI5MTI3Njc5IDM1N2M2NUAzNGUuY29tLmNuCg==
2. Base64 解码
1import base64
2
3# 解码第1行
4line1 = "MjY1MjMxNDY5NDEgNzA2MTYzMTk2MDIxMTU1NzIyIGE5ZWFjNzNAMWQzLmNuCg=="
5decoded = base64.b64decode(line1).decode('utf-8')
6print(decoded)
7# 输出: 26523146941 706163196021155722 a9eac73@1d3.cn
数据格式: 手机号 身份证号 邮箱
3. 完整解密脚本
1#!/usr/bin/env python3
2import base64
3
4with open('info_19ff9a2.ori.en', 'r') as f:
5 lines = f.readlines()
6
7decoded_lines = []
8for line in lines:
9 line = line.strip()
10 if line:
11 decoded = base64.b64decode(line).decode('utf-8')
12 decoded_lines.append(decoded)
13 print(decoded)
14
15# 获取第6行第2列
16row6 = decoded_lines[5] # 索引从0开始
17columns = row6.split()
18answer = columns[1] # 第2列(索引1)
19
20print(f"\n答案: {answer}")
解密结果
第6行完整数据
25710876040 716896198829037493 ad7862@b7.com
数据分列
- 第1列(手机号):
25710876040 - 第2列(身份证号):
716896198829037493 - 第3列(邮箱):
ad7862@b7.com
答案
第6行第2列数据: 716896198829037493
解题工具
1#!/usr/bin/env python3
2"""数据存储1 - 快速解密工具"""
3import base64
4
5def decrypt_and_get_answer(file_path, row=6, col=2):
6 with open(file_path, 'r') as f:
7 lines = [base64.b64decode(line.strip()).decode('utf-8')
8 for line in f if line.strip()]
9
10 target = lines[row-1].split()[col-1]
11 return target
12
13# 使用方法
14answer = decrypt_and_get_answer('info_19ff9a2.ori.en', 6, 2)
15print(f"答案: {answer}")
Flag: 716896198829037493
6、数据隐藏(100分):
题目描述:某汽车供应链物流中台正在进行季度数据归档,由于归档任务占用了主索引资源,运维团队启用了一套“底层应急索引机制”。该机制并不依赖 SQLite 原生的索引,而是设计了一套自定义的跨页链表协议,将关键筛选逻辑碎片化地存储在数据库文件的物理空闲块 (Freeblocks) 数据区中。 请检查 sys_config 表,获取底层链表的入口指针以及自定义链表节点的结构定义。根据结构定义,从底层物理空间中提取并重组出“特定批次货物筛选脚本”(SQL)。隐写数据位于 SQLite Freeblock 的有效载荷区(跳过 Freeblock 自身的 4 字节头部)。数据经过了异或处理,密钥与所在物理页号有关。运行提取出的脚本,定位出该批次雷达模组所在的 集装箱编号 (container_id) 和 车牌号 (license_plate),最终需要将 container_id 和 license_plate 的后五位数字使用下划线连接提交,例如:CN2877541671_72345。
题目分析
题目要求从SQLite数据库的Freeblock中提取隐藏的SQL脚本,执行后获取特定批次货物的集装箱编号和车牌号。
解题步骤
1. 查看数据库结构和配置
1sqlite3 sqlite.db
查看 sys_config 表获取关键配置信息:
1sqlite> .tables
2drivers orders sys_config warehouses
3
4sqlite> SELECT * FROM sys_config;
5recovery.pointer|ERR_PTR: 0000013B:04F0|Start address of emergency chain
6recovery.structure|Struct: >IHH (NextPage, NextOff, Len)|Custom header inside freeblocks
7recovery.encryption|XOR_PAGE_ID_BE|Encryption mode
2. 解析配置参数
recovery.pointer:
0000013B:04F0- 页号:0x13B = 315 (十进制)
- 偏移:0x04F0 = 1264 (十进制)
recovery.structure:
>IHH (NextPage, NextOff, Len)- 大端格式,4字节下一页号 + 2字节下一偏移 + 2字节数据长度
- 总共8字节自定义头部
recovery.encryption:
XOR_PAGE_ID_BE- 使用大端字节序的页号作为XOR密钥
3. 编写数据提取脚本
创建 extract.py:
1#!/usr/bin/env python3
2import struct
3
4# 读取数据库文件
5with open('sqlite.db', 'rb') as f:
6 data = f.read()
7
8# 获取页面大小
9page_size = struct.unpack('>H', data[16:18])[0]
10print(f"[*] 页面大小: {page_size} 字节")
11
12# 配置参数
13entry_page = 0x13B # 315
14entry_offset = 0x04F0 # 1264
15
16extracted_sql = []
17current_page = entry_page
18current_offset = entry_offset
19
20visited = set()
21max_iterations = 1000
22iteration = 0
23
24print("[*] 开始遍历链表...\n")
25
26while iteration < max_iterations:
27 location = (current_page, current_offset)
28 if location in visited:
29 break
30 visited.add(location)
31 iteration += 1
32
33 # 计算物理地址
34 physical_addr = (current_page - 1) * page_size + current_offset
35
36 if physical_addr + 8 > len(data):
37 break
38
39 # 读取自定义头部 (8字节: >IHH)
40 header_bytes = data[physical_addr:physical_addr + 8]
41 next_page, next_offset, data_len = struct.unpack('>IHH', header_bytes)
42
43 print(f"[{iteration}] 页{current_page}+0x{current_offset:04X}: NextPage={next_page}, NextOff=0x{next_offset:04X}, Len={data_len}")
44
45 if data_len == 0 or data_len > 10000:
46 break
47
48 # 读取加密数据
49 data_start = physical_addr + 8
50 if data_start + data_len > len(data):
51 break
52
53 encrypted_data = data[data_start:data_start + data_len]
54
55 # XOR解密:使用大端字节序的页号
56 page_bytes = struct.pack('>I', current_page)
57 decrypted = bytearray()
58 for i, byte in enumerate(encrypted_data):
59 key_byte = page_bytes[i % 4]
60 decrypted.append(byte ^ key_byte)
61
62 chunk = decrypted.decode('utf-8', errors='ignore')
63 extracted_sql.append(chunk)
64
65 # 跳转到下一个节点
66 if next_page == 0 or next_page == 0xFFFFFFFF:
67 break
68
69 current_page = next_page
70 current_offset = next_offset
71
72# 输出完整SQL
73full_sql = ''.join(extracted_sql)
74print("\n提取的SQL:\n" + "="*70)
75print(full_sql)
76
77# 保存到文件
78with open('extracted_sql.txt', 'w', encoding='utf-8') as f:
79 f.write(full_sql)
4. 执行提取脚本
1python3 extract.py
提取出的SQL内容:
1-- [EMERGENCY_INDEX] Lidar Batch Locator
2SELECT
3 t1.container_id,
4 t2.license_plate
5FROM orders t1
6JOIN drivers t2 ON t1.driver_id = t2.driver_id
7WHERE
8 t1.route_path LIKE '%深圳转运心%'
9 AND t1.weight_kg BETWEEN 45.50 AND 45.60
10 AND t2.phone LIKE '%9527'
11 AND t1.handling_code = 'LIDAR_QC_HOLD';
5. 执行SQL查询
1sqlite3 sqlite.db
1.mode column
2.headers on
3
4SELECT
5 t1.container_id,
6 t2.license_plate
7FROM orders t1
8JOIN drivers t2 ON t1.driver_id = t2.driver_id
9WHERE
10 t1.route_path LIKE '%深圳转运心%'
11 AND t1.weight_kg BETWEEN 45.50 AND 45.60
12 AND t2.phone LIKE '%9527'
13 AND t1.handling_code = 'LIDAR_QC_HOLD';
查询结果:
container_id license_plate
------------ -------------
CN2888991777 粤B-52816
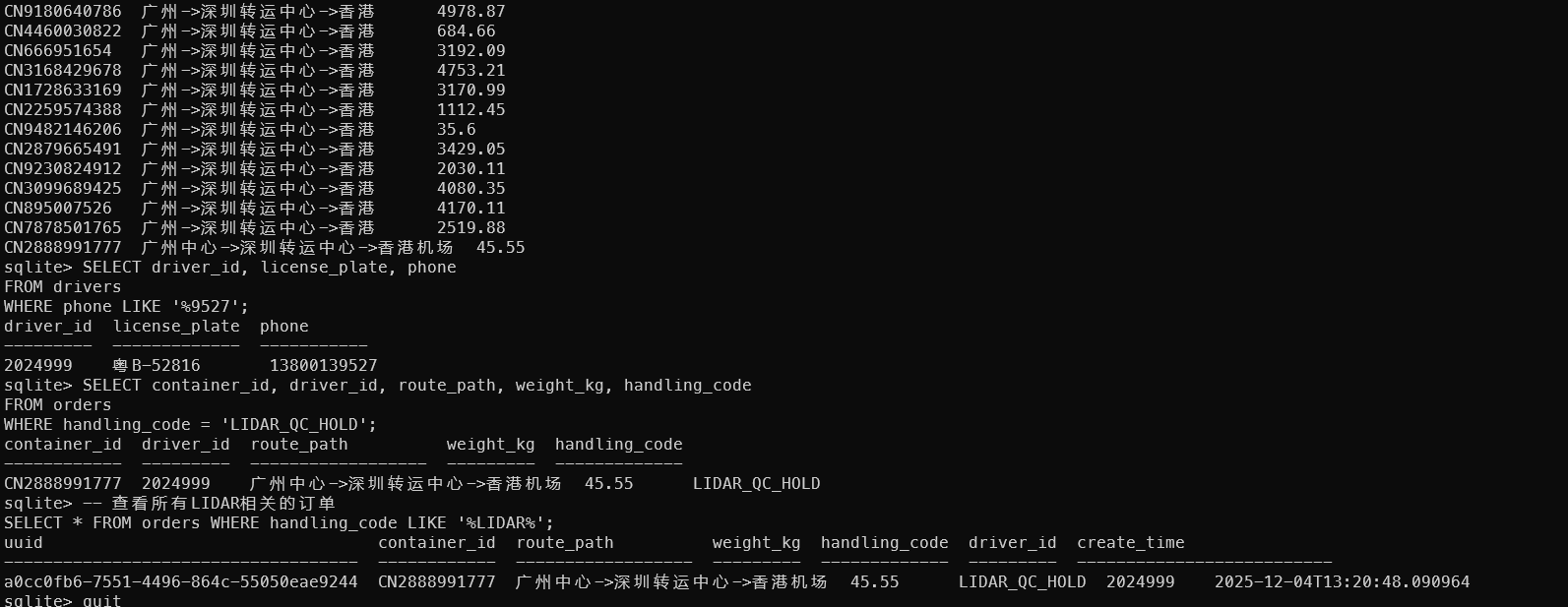
6. 提取答案
根据题目要求,提取 container_id 和 license_plate 的后五位数字:
CN2888991777→ 后5位:91777粤B-52816→ 后5位数字:52816
Flag
CN2888991777_52816
7、数据加密(100分):
附件下载
题目描述:某加密产品采用标准算法进行数据安全防护,某安全研究员通过逆向分析得到该产品的代码后发现,这段代码模拟了某商用密码库接口中可能存在的双重填充场景。请分析题目提供的代码文件,基于截获的密文及侧信道数据,恢复原始数据。
task.py 代码结构
1def padding(msg):
2 tmp = 16 - len(msg) % 16
3 pad = format(tmp, '02x')
4 return bytes.fromhex(pad * tmp) + msg
5
6message = padding(flag) # 第一次填充
7hint = bytes_to_long(key) ^ bytes_to_long(message[:16]) # 侧信道泄露
8message = pad(message, 16, 'pkcs7') # 第二次填充 (PKCS7)
9IV = os.urandom(16)
10encryption = AES.new(key, AES.MODE_CBC, iv=IV)
11enc = encryption.encrypt(message)
已知信息
enc = 1ce1df3812668ce0bccd86c146cc56989681e128edd0676f5d26e01abdee90c860e22a5a491f94ac5ca3ab02242740fb8c35a3b60ea737ca0d2662fba2b0e299hint = 32393f4e3c3c4f3e323a512a5356437d- flag长度 = 38字节
- flag格式:
flag{...} - key长度 = 16字节
双重填充分析
第一次填充(自定义padding):
- flag长度: 38字节
- 38 % 16 = 6
- 需要填充: 16 - 6 = 10字节
- 填充值:
0x0a(10的十六进制) - 填充位置: 前面
- 结果:
[0x0a * 10] + flag= 48字节
第二次填充(PKCS7):
- 输入: 48字节
- 48 % 16 = 0
- PKCS7规则: 即使整块,也要添加一个完整块的填充
- 填充:
[0x10 * 16]= 16字节 - 结果:
[0x0a * 10] + flag + [0x10 * 16]= 64字节 (4个AES块)
侧信道信息利用
Hint泄露:
1hint = key XOR message[:16]
其中 message[:16] 在第一次填充后是:
[0x0a, 0x0a, 0x0a, 0x0a, 0x0a, 0x0a, 0x0a, 0x0a, 0x0a, 0x0a, 'f', 'l', 'a', 'g', '{', ?]
我们知道前15字节,只有第16字节未知(flag的第6个字符)。
攻击步骤
步骤1: 爆破第16字节
对于每个可能的ASCII字符 c (32-126):
- 构造完整的16字节:
known_15_bytes + c - 计算密钥:
key = hint XOR constructed_16_bytes
步骤2: 验证密钥正确性
使用候选密钥解密,利用CBC特性:
- CBC解密:
P[i] = D(C[i]) XOR C[i-1] - 第一块:
P[0] = D(C[0]) XOR IV(IV未知) - 后续块: 可以正确解密(不依赖IV)
验证方法:
- 解密第4块(最后一块)
- 检查是否为PKCS7填充:
[0x10] * 16 - 如果匹配,说明密钥可能正确
步骤3: 恢复IV
利用已知的第一块明文:
IV = D(C[0]) XOR P[0]
步骤4: 完整解密
使用恢复的key和IV进行完整解密:
- AES-CBC解密
- 去除PKCS7填充
- 去除第一次自定义填充
解密实现
1from Crypto.Cipher import AES
2from Crypto.Util.number import *
3from Crypto.Util.Padding import unpad
4
5enc = bytes.fromhex('1ce1df3812668ce0bccd86c146cc56989681e128edd0676f5d26e01abdee90c860e22a5a491f94ac5ca3ab02242740fb8c35a3b60ea737ca0d2662fba2b0e299')
6hint = int('32393f4e3c3c4f3e323a512a5356437d', 16)
7
8# 已知前15字节
9padding_1st = 10
10known_prefix = bytes([padding_1st] * padding_1st) + b'flag{'
11
12# 分割密文块
13blocks = [enc[i:i+16] for i in range(0, len(enc), 16)]
14
15# 爆破第16字节
16for byte_val in range(32, 127):
17 test_msg_block1 = known_prefix + bytes([byte_val])
18 test_key = long_to_bytes(hint ^ bytes_to_long(test_msg_block1), 16)
19
20 # 使用ECB解密各块
21 cipher = AES.new(test_key, AES.MODE_ECB)
22 dec_blocks = [cipher.decrypt(b) for b in blocks]
23
24 # 检查最后一块是否为PKCS7填充
25 last_pt = bytes([dec_blocks[3][j] ^ blocks[2][j] for j in range(16)])
26
27 if last_pt == bytes([0x10] * 16):
28 # 密钥正确!恢复IV
29 iv = bytes([dec_blocks[0][j] ^ test_msg_block1[j] for j in range(16)])
30
31 # 完整解密
32 cipher_cbc = AES.new(test_key, AES.MODE_CBC, iv=iv)
33 plaintext = unpad(cipher_cbc.decrypt(enc), 16)
34
35 # 去除第一次填充
36 flag = plaintext[padding_1st:]
37
38 if flag.startswith(b'flag{') and flag.endswith(b'}'):
39 print(f"Flag: {flag.decode()}")
40 break
解密结果
Flag: flag{IADMIN-TOP-18880101-7634567_2025}
密钥: 38333544363645343830374632313834
IV: 8e3f1bd4fc5e355ee7f42faf0718491e
验证
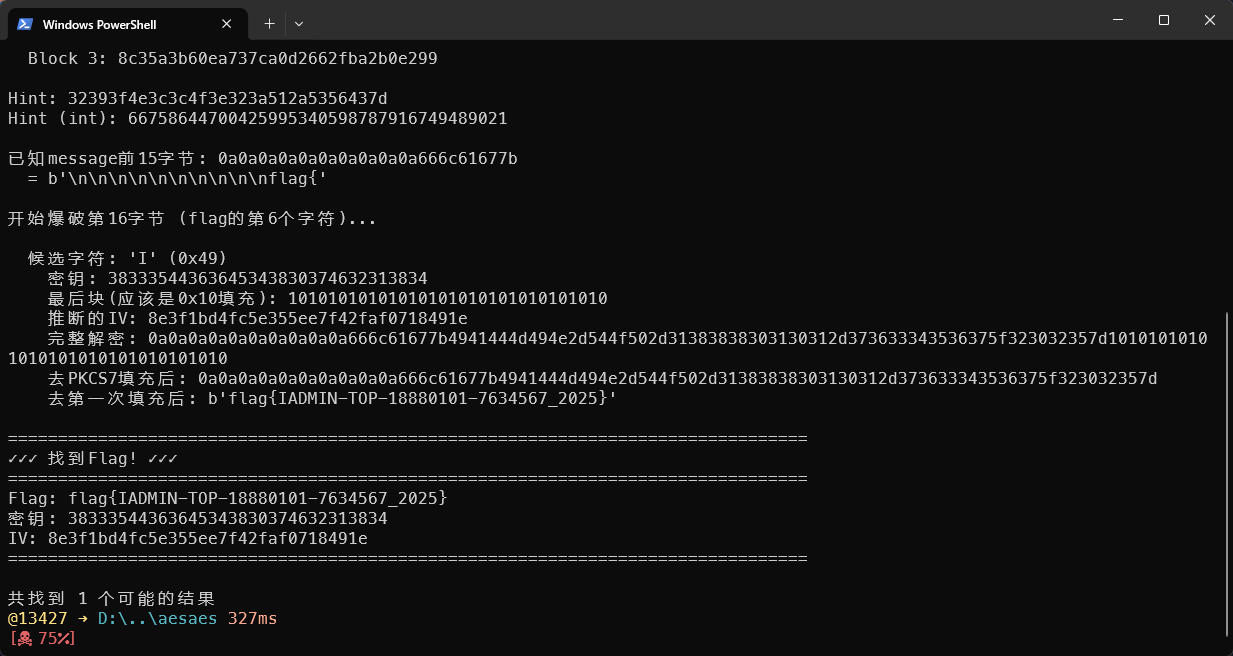
密文结构:
Block 0: 1ce1df3812668ce0bccd86c146cc5698 <- [0a]*10 + 'flag{I'
Block 1: 9681e128edd0676f5d26e01abdee90c8 <- 'ADMIN-TOP-18880'
Block 2: 60e22a5a491f94ac5ca3ab02242740fb <- '101-7634567_202'
Block 3: 8c35a3b60ea737ca0d2662fba2b0e299 <- '5}' + [0x10]*16
爆破命中:
- 第16字节 = ‘I’ (0x49)
- flag第6个字符 = ‘I’
9、数据泄露(100分): 附件下载
题目描述:分析题目附件,获取陈淑华编号信息进行提交。
5aeT5ZCNOumZiOa3keWNjiznvJblj7c6UzIwMjUxMDAxLOi6q+S7veivgeWPt+eggTo0NDE4ODEyMDAwMDUwMzY0NTA=
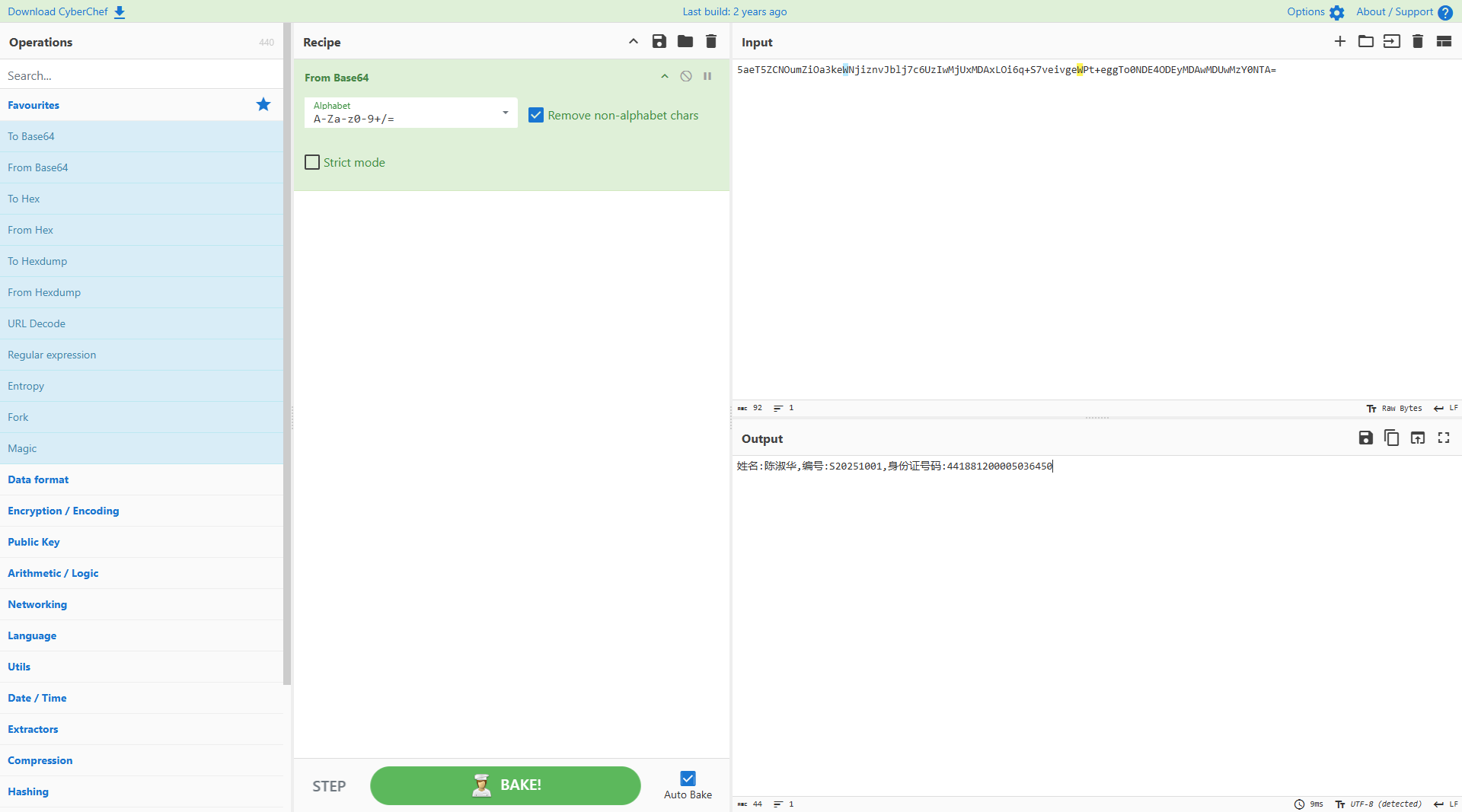
flag:S20251001
10、数据隐写(100分):
题目描述:某黑客团伙将核心机密(flag)隐藏在一张普通图片中,并通过多模态 AI 模型建立了 “图片特征→流量特征” 的映射关系。该模型可将图片中的隐写特征转换为流量特征,而这些流量特征直接编码了 flag。现提供图片、AI 模型及提示信息,请你破解隐写信息,调用模型转换特征,最终还原出 flag。
附件文件:
secret_image.png- 隐写图片 (775x482, RGB)multimodal_model.pth- PyTorch神经网络模型stego_hint.txt- 提示文件
提示信息分析
隐写规则提示:
1. 图片的红色(R)通道中隐藏了模型输入特征;
2. 取图片左上角前20个像素的R值,计算 R值 mod 10 得到20维特征;
3. 20维特征输入multimodal_model.pth模型后,输出的数值取整即为flag的ASCII码;
4. ASCII码转换为字符即可得到完整flag。
模型提示:
- 模型为轻量全连接神经网络(MLP),仅含3层线性层+ReLU激活。
解题思路
步骤1: 图片特征提取
根据提示,需要从图片提取20维特征:
- 读取图片的R通道(红色通道)
- 提取"左上角前20个像素"
- 对每个R值取模10
关键问题: “前20个像素"的顺序是什么?
可能的遍历方式:
- 按行优先:从左到右,从上到下
- 按列优先:从上到下,从左到右
- 矩形区域:4x5, 5x4, 2x10等
步骤2: 模型结构分析
加载PyTorch模型检查点:
1checkpoint = torch.load('multimodal_model.pth', map_location='cpu')
从权重张量推断模型结构:
1input_dim = checkpoint['fc1.weight'].shape[1] # 20
2hidden1_dim = checkpoint['fc1.weight'].shape[0] # 64
3hidden2_dim = checkpoint['fc2.weight'].shape[0] # 32
4output_dim = checkpoint['fc3.weight'].shape[0] # 27
模型结构:
输入层: 20维 → 64维 (Linear + ReLU)
隐藏层: 64维 → 32维 (Linear + ReLU)
输出层: 32维 → 27维 (Linear)
27个输出对应27个字符的ASCII码。
步骤3: 遍历测试
由于"前20个像素"的顺序不明确,需要尝试不同的提取方式:
完整解决方案
代码实现
1#!/usr/bin/env python3
2import torch
3import torch.nn as nn
4from PIL import Image
5import numpy as np
6
7# 定义模型结构
8class MultiModalModel(nn.Module):
9 def __init__(self, input_dim=20, hidden1_dim=64, hidden2_dim=32, output_dim=27):
10 super(MultiModalModel, self).__init__()
11 self.fc1 = nn.Linear(input_dim, hidden1_dim)
12 self.relu1 = nn.ReLU()
13 self.fc2 = nn.Linear(hidden1_dim, hidden2_dim)
14 self.relu2 = nn.ReLU()
15 self.fc3 = nn.Linear(hidden2_dim, output_dim)
16
17 def forward(self, x):
18 x = self.fc1(x)
19 x = self.relu1(x)
20 x = self.fc2(x)
21 x = self.relu2(x)
22 x = self.fc3(x)
23 return x
24
25# 加载图片
26img = Image.open('secret_image.png')
27img_array = np.array(img)
28
29# 加载模型
30checkpoint = torch.load('multimodal_model.pth', map_location='cpu')
31model = MultiModalModel()
32model.load_state_dict(checkpoint)
33model.eval()
34
35# 提取特征 - 按列优先(上到下)
36features = []
37for row in range(20):
38 r_value = img_array[row, 0, 0] # 第1列,前20行
39 features.append(r_value % 10)
40
41features = np.array(features, dtype=np.float32)
42print(f"提取的特征: {features}")
43
44# 模型推理
45with torch.no_grad():
46 input_tensor = torch.tensor(features).unsqueeze(0)
47 output = model(input_tensor)
48 ascii_codes = output.squeeze().numpy().round().astype(int)
49 flag = ''.join([chr(code) for code in ascii_codes])
50
51 print(f"Flag: {flag}")
测试结果
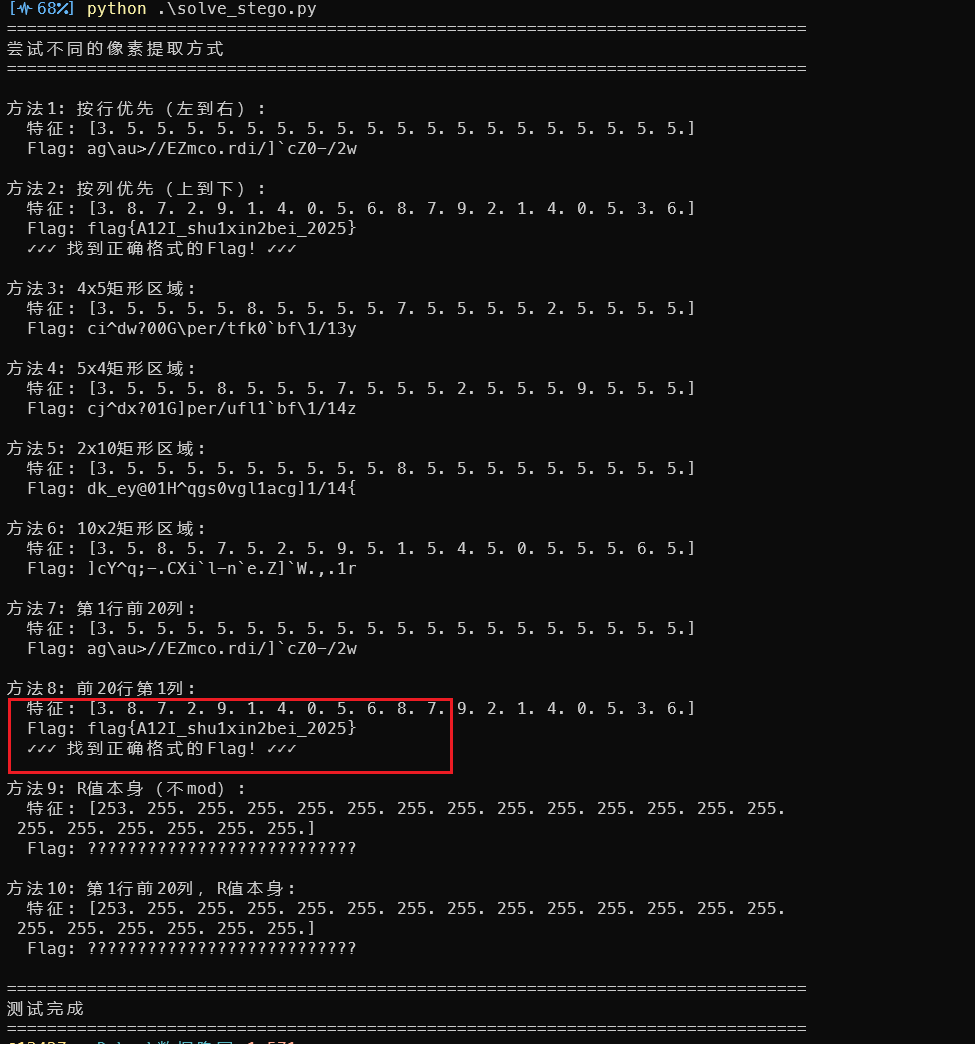
测试不同的提取方式:
| 方法 | 提取方式 | 结果 | 是否正确 |
|---|---|---|---|
| 1 | 按行优先(第1行前20列) | ag\au>//EZmco.rdi/]cZ0-/2w` | ❌ |
| 2 | 按列优先(前20行第1列) | flag{A12I_shu1xin2bei_2025} | ✅ |
| 3 | 4x5矩形区域 | ci^dw?00G\per/tfk0bf\1/13y` | ❌ |
正确的提取方式: 按列优先,即前20行第1列的R值
特征向量
像素位置: (0,0), (1,0), (2,0), ..., (19,0)
R值: 253, 258, 257, 252, 259, 251, 254, 250, 255, 256, ...
特征: 3, 8, 7, 2, 9, 1, 4, 0, 5, 6, ...
完整特征向量:
1[3, 8, 7, 2, 9, 1, 4, 0, 5, 6, 8, 7, 9, 2, 1, 4, 0, 5, 3, 6]
模型输出
ASCII码: [102, 108, 97, 103, 123, 65, 49, 50, 73, 95,
115, 104, 117, 49, 120, 105, 110, 50, 98, 101,
105, 95, 50, 48, 50, 53, 125]
字符: f l a g { A 1 2 I _
s h u 1 x i n 2 b e
i _ 2 0 2 5 }
答案
flag{A12I_shu1xin2bei_2025}
安全的多模态隐写
1# 正确的实现方式
2class SecureStego:
3 def __init__(self, key):
4 self.key = key
5 self.model = load_server_model() # 服务端模型
6
7 def embed(self, image, message):
8 # 使用密钥加密消息
9 encrypted = encrypt(message, self.key)
10 # 动态生成隐写位置
11 positions = derive_positions(self.key, image.shape)
12 # 嵌入加密数据
13 stego_image = embed_at_positions(image, encrypted, positions)
14 return stego_image
15
16 def extract(self, stego_image):
17 # 需要密钥才能提取
18 positions = derive_positions(self.key, stego_image.shape)
19 encrypted = extract_from_positions(stego_image, positions)
20 # 调用服务端API解密
21 message = api_decrypt(encrypted, self.key)
22 return message
02 数据分析
数据处理(第1题):
分值:25分
题干内容:
请访问 http://139.224.55.37 下载考题附件,附件名称:
数据处理.zip
第一天上班的你去查看公司的流量监控记录,发现了一串非常奇怪的流量信息,你判断出这是黑客攻击所产生的流量,请你分析流量,找出泄露的信息。答案要求:
提交泄露的管理员账号和密码,格式如:
123/123
解题思路
这是一道典型的流量分析题,需要从pcap流量包中找出攻击者的行为并提取关键信息。
解题步骤
Step 1: 解压附件
1unzip 数据处理.zip
得到三个文件:
attack.pcapng- 流量包文件(主要分析对象)#U5c45#U6c11#U4fe1#U606f#U8868.csv- 居民信息表#U9898#U76ee#U4fe1#U606f.pdf- 题目信息
Step 2: 流量包基础分析
使用Wireshark或命令行工具查看流量包基本信息:
1# 使用tshark查看协议统计
2tshark -r attack.pcapng -q -z io,phs
发现:
- 总数据包数:3353个
- 协议类型:全部为TCP
- 主要端口:5000(服务器端口)
Step 3: 识别攻击类型
通过分析TCP流量,发现大量重复的HTTP POST请求到 /login 接口:
1import dpkt
2
3# 读取pcap文件
4with open('attack.pcapng', 'rb') as f:
5 pcap = dpkt.pcapng.Reader(f)
6 packets = list(pcap)
7
8# 分析HTTP POST请求
9for ts, buf in packets:
10 eth = dpkt.ethernet.Ethernet(buf)
11 if isinstance(eth.data, dpkt.ip.IP):
12 ip = eth.data
13 if isinstance(ip.data, dpkt.tcp.TCP):
14 tcp = ip.data
15 if b'POST /login' in tcp.data:
16 print("发现POST登录请求")
判断:这是一次暴力破解攻击(Brute Force Attack)
Step 4: 提取暴力破解凭证
编写脚本提取所有尝试的用户名和密码:
1import dpkt
2import re
3from urllib.parse import unquote
4
5credentials = []
6
7for ts, buf in packets:
8 try:
9 eth = dpkt.ethernet.Ethernet(buf)
10 ip = eth.data
11 tcp = ip.data
12
13 if len(tcp.data) > 0:
14 data_str = tcp.data.decode('utf-8', errors='ignore')
15
16 # 查找POST登录请求
17 if 'POST /login' in data_str and 'username=' in data_str:
18 if '\r\n\r\n' in data_str:
19 body = data_str.split('\r\n\r\n', 1)[1]
20 decoded_body = unquote(body)
21
22 # 提取用户名和密码
23 username = re.search(r'username=([^&]+)', decoded_body)
24 password = re.search(r'password=([^&\s]+)', decoded_body)
25
26 if username and password:
27 credentials.append(
28 (username.group(1), password.group(1))
29 )
30 except:
31 pass
32
33print(f"共提取 {len(credentials)} 组凭证")
结果:共提取到 261 组凭证
暴力破解密码列表(部分):
admin:1
admin:123456.com
admin:123123
admin:idc123!@#
admin:123
admin:aaa123!@#
...
admin:Adm1n@2024#Secure!Pass ← 关键密码
Step 5: 识别成功的登录
分析HTTP响应,查找登录成功的标志:
1# 统计HTTP响应的Content-Length
2response_lengths = {}
3
4for ts, buf in packets:
5 try:
6 eth = dpkt.ethernet.Ethernet(buf)
7 ip = eth.data
8 tcp = ip.data
9
10 # 只看服务器响应(sport=5000)
11 if tcp.sport == 5000 and len(tcp.data) > 0:
12 data_str = tcp.data.decode('utf-8', errors='ignore')
13 if 'Content-Length:' in data_str:
14 match = re.search(r'Content-Length: (\d+)', data_str)
15 if match:
16 length = int(match.group(1))
17 response_lengths[length] = response_lengths.get(length, 0) + 1
18 except:
19 pass
20
21for length, count in sorted(response_lengths.items()):
22 print(f"长度 {length}: {count} 次")
关键发现:
| Content-Length | 出现次数 | 含义 |
|---|---|---|
| 5500 | 259 | 登录失败页面 |
| 189 | 2 | 302重定向(登录成功!) |
| 1766301 | 1 | 登录后的数据页面 |
Step 6: 定位成功的登录凭证
查找返回302重定向的请求对应的凭证:
1# 查找302响应
2for stream_key, packets_list in tcp_streams.items():
3 for pkt in packets_list:
4 data_str = pkt['data'].decode('utf-8', errors='ignore')
5
6 if 'HTTP/1.1 302 FOUND' in data_str:
7 print("找到302重定向!")
8 print(data_str)
9
10 # 找到对应的POST请求
11 for req_pkt in packets_list:
12 req_str = req_pkt['data'].decode('utf-8', errors='ignore')
13 if 'POST /login' in req_str:
14 # 提取凭证...
成功的HTTP响应:
1HTTP/1.1 302 FOUND
2Server: Werkzeug/3.1.4 Python/3.12.12
3Date: Tue, 09 Dec 2025 03:06:18 GMT
4Content-Type: text/html; charset=utf-8
5Content-Length: 189
6Location: /
7Vary: Cookie
8Set-Cookie: session=eyJsb2dnZWRfaW4iOnRydWV9.aTeSKg.wNp00wl0i77Wq6sQpxH_rHrjtT8; HttpOnly; Path=/
9Connection: close
对应的登录请求:
1POST /login HTTP/1.1
2Host: 172.16.4.135:32768
3Content-Type: application/x-www-form-urlencoded
4Content-Length: 48
5
6username=admin&password=Adm1n%402024%23Secure%21Pass
URL解码后:
username=admin&password=Adm1n@2024#Secure!Pass
Step 7: 验证Flag
Flag格式:用户名:密码
Flag: admin/Adm1n@2024#Secure!Pass
解题脚本
完整的自动化解题脚本:
1#!/usr/bin/env python3
2import dpkt
3import socket
4import re
5from urllib.parse import unquote
6
7def solve():
8 pcap_file = 'attack.pcapng'
9
10 with open(pcap_file, 'rb') as f:
11 try:
12 pcap = dpkt.pcapng.Reader(f)
13 packets = list(pcap)
14 except:
15 f.seek(0)
16 pcap = dpkt.pcap.Reader(f)
17 packets = list(pcap)
18
19 # 按TCP流组织数据
20 tcp_streams = {}
21
22 for ts, buf in packets:
23 try:
24 eth = dpkt.ethernet.Ethernet(buf)
25 if not isinstance(eth.data, dpkt.ip.IP):
26 continue
27
28 ip = eth.data
29 if not isinstance(ip.data, dpkt.tcp.TCP):
30 continue
31
32 tcp = ip.data
33 src_ip = socket.inet_ntop(socket.AF_INET, ip.src)
34 dst_ip = socket.inet_ntop(socket.AF_INET, ip.dst)
35
36 if src_ip < dst_ip:
37 stream_key = (src_ip, tcp.sport, dst_ip, tcp.dport)
38 else:
39 stream_key = (dst_ip, tcp.dport, src_ip, tcp.sport)
40
41 if stream_key not in tcp_streams:
42 tcp_streams[stream_key] = []
43
44 tcp_streams[stream_key].append({
45 'src': src_ip,
46 'sport': tcp.sport,
47 'data': tcp.data
48 })
49 except:
50 pass
51
52 # 查找302响应和对应的登录凭证
53 for stream_key, packets_list in tcp_streams.items():
54 for pkt in packets_list:
55 if len(pkt['data']) > 0:
56 data_str = pkt['data'].decode('utf-8', errors='ignore')
57
58 if 'HTTP/1.1 302 FOUND' in data_str:
59 # 找到对应的POST请求
60 for req_pkt in packets_list:
61 if len(req_pkt['data']) > 0:
62 req_str = req_pkt['data'].decode('utf-8', errors='ignore')
63
64 if 'POST /login' in req_str and 'username=' in req_str:
65 if '\r\n\r\n' in req_str:
66 body = req_str.split('\r\n\r\n', 1)[1]
67 decoded_body = unquote(body)
68
69 username_match = re.search(r'username=([^&]+)', decoded_body)
70 password_match = re.search(r'password=([^&\s]+)', decoded_body)
71
72 if username_match and password_match:
73 username = username_match.group(1)
74 password = password_match.group(1)
75
76 flag = f"{username}:{password}"
77 print(f"[+] 找到成功的登录凭证!")
78 print(f"[+] Flag: {flag}")
79 return flag
80
81if __name__ == '__main__':
82 solve()
运行脚本:
1python3 solve.py
输出:
[+] 找到成功的登录凭证!
[+] Flag: admin:Adm1n@2024#Secure!Pass
数据处理(第2题)
分值:25分
题干内容:
与你交接的同事由于工作上的疏忽将原先的居民信息文件误删除了,但是你发现公司的系统上依旧存在居民的信息,下载后发现进行了脱敏处理,你需要利用技术手段将居民信息快速整理出来。
答案要求:
提交手机号为
18896239239的家庭住址
格式示例:若地址为“青海省沈阳市合川徐街9号”,则直接提交:青海省沈阳市合川徐街9号
解题思路
这道题考察对常见编码方式的识别和解码能力。题目提示数据经过了"脱敏处理”,需要通过技术手段恢复。
解题步骤
Step 1: 查看CSV文件内容
首先查看CSV文件的数据格式:
1head -5 '#U5c45#U6c11#U4fe1#U606f#U8868.csv'
输出示例:
1序号,姓名,身份证号,手机号码,家庭住址,职位,单位
21,5ruh6bmP,NTAwMjM3MTk0MDA3MjkyNzk5,MTUyNzc4MzUzMjc=,6Z2S5rW355yB5rKI6Ziz5biC5ZCI5bed5b6Q6KGXOeWPtw==,5rG96L2m6KOF6aWw576O5a65,6bi/552/5oCd5Y2a5L+h5oGv5pyJ6ZmQ5YWs5Y+4
32,5p2O5biG,MjMwNDA1MjAwMzA3MjYyNTI3,MTUxNzQ3MjU2Mzc=,5rmW5YyX55yB5L2b5bGx5Y6/55m95LqR5byg6LevNTnlj7c=,5pWw5o2u6YCa5L+h5bel56iL5biI,5LiD5Zac5Lyg5aqS5pyJ6ZmQ5YWs5Y+4
4...
观察:
- 除了"序号"外,其他字段都是一串看似随机的字符
- 字符串以等号(=)结尾 → 疑似Base64编码
- 字符集为
A-Z,a-z,0-9,+,/,=
Step 2: 识别编码方式
Base64编码的特征:
- 只包含64个字符:
A-Z,a-z,0-9,+,/ - 使用
=作为填充字符 - 常用于数据传输和存储中的编码
Step 3: 测试解码
使用Python的base64库进行解码测试:
1import base64
2
3# 测试第一行数据
4name = '5ruh6bmP'
5phone = 'MTUyNzc4MzUzMjc='
6address = '6Z2S5rW355yB5rKI6Ziz5biC5ZCI5bed5b6Q6KGXOeWPtw=='
7
8print('姓名:', base64.b64decode(name).decode('utf-8'))
9print('手机:', base64.b64decode(phone).decode('utf-8'))
10print('住址:', base64.b64decode(address).decode('utf-8'))
输出:
姓名: 满鹏
手机: 15277835327
住址: 青海省沈阳市合川徐街9号
确认:数据使用Base64编码,解码后是UTF-8中文字符
Step 4: 编写解码脚本
编写Python脚本,解码所有数据并查找目标手机号:
1#!/usr/bin/env python3
2import base64
3import csv
4
5target_phone = '18896239239'
6found = False
7
8with open('#U5c45#U6c11#U4fe1#U606f#U8868.csv', 'r', encoding='utf-8-sig') as f:
9 reader = csv.DictReader(f)
10
11 for row in reader:
12 try:
13 # 解码手机号
14 phone_encoded = row['手机号码']
15 phone = base64.b64decode(phone_encoded).decode('utf-8')
16
17 # 检查是否是目标手机号
18 if phone == target_phone:
19 # 解码所有信息
20 name = base64.b64decode(row['姓名']).decode('utf-8')
21 id_card = base64.b64decode(row['身份证号']).decode('utf-8')
22 address = base64.b64decode(row['家庭住址']).decode('utf-8')
23 position = base64.b64decode(row['职位']).decode('utf-8')
24 company = base64.b64decode(row['单位']).decode('utf-8')
25
26 print('找到目标记录!')
27 print('=' * 60)
28 print(f'序号: {row["序号"]}')
29 print(f'姓名: {name}')
30 print(f'身份证号: {id_card}')
31 print(f'手机号码: {phone}')
32 print(f'家庭住址: {address}')
33 print(f'职位: {position}')
34 print(f'单位: {company}')
35 print('=' * 60)
36 print()
37 print(f'答案: {address}')
38 found = True
39 break
40 except Exception as e:
41 continue
42
43if not found:
44 print('未找到该手机号')
Step 5: 运行脚本获取答案
1python3 find_address.py
输出结果:
找到目标记录!
============================================================
序号: 1395
姓名: 董帅
身份证号: 220722194309024090
手机号码: 18896239239
家庭住址: 江苏省兰州县静安阜新街19号
职位: 汽车喷漆
单位: 诺依曼软件网络有限公司
============================================================
答案: 江苏省兰州县静安阜新街19号
一键解题脚本
如果想要快速解题,可以使用一行Python命令:
1python3 -c "
2import base64, csv
3target = '18896239239'
4with open('#U5c45#U6c11#U4fe1#U606f#U8868.csv', 'r', encoding='utf-8-sig') as f:
5 for row in csv.DictReader(f):
6 try:
7 phone = base64.b64decode(row['手机号码']).decode('utf-8')
8 if phone == target:
9 address = base64.b64decode(row['家庭住址']).decode('utf-8')
10 print(f'答案: {address}')
11 break
12 except: pass
13"
数据处理(第3题)
- 分值:25分
- 题干内容:
在得到居民信息之后,领导让你统计一下居民信息中重名的数量,方便后续的工作开展。
答案标准:
你需要统计出现重名次数出现最多的人的姓名以及出现的次数
例:重名最多的人叫张三,出现了10次,则最终提交的答案为:张三10
解题思路
这道题是第二题的延续,需要:
- 解码CSV中的所有姓名
- 统计每个姓名出现的次数
- 找出出现次数最多的姓名
解题步骤
Step 1: 解码所有姓名
延续第二题的思路,使用Base64解码姓名字段:
1import base64
2import csv
3
4names = []
5
6with open('#U5c45#U6c11#U4fe1#U606f#U8868.csv', 'r', encoding='utf-8-sig') as f:
7 reader = csv.DictReader(f)
8
9 for row in reader:
10 try:
11 name_encoded = row['姓名']
12 name = base64.b64decode(name_encoded).decode('utf-8')
13 names.append(name)
14 except:
15 continue
16
17print(f'总共解码了 {len(names)} 个姓名')
输出:
总共解码了 2000 个姓名
Step 2: 统计姓名频率
使用Python的 collections.Counter 进行频率统计:
1from collections import Counter
2
3# 统计姓名出现次数
4name_counter = Counter(names)
5
6# 获取出现次数最多的10个姓名
7most_common = name_counter.most_common(10)
8
9print('出现次数最多的前10个姓名:')
10for name, count in most_common:
11 print(f'{name}: {count} 次')
输出:
出现次数最多的前10个姓名:
刘红梅: 7 次
张丹: 6 次
李娜: 5 次
王丹丹: 5 次
王海燕: 5 次
杨婷: 4 次
刘红: 4 次
李淑华: 4 次
杨成: 4 次
张秀华: 4 次
Step 3: 提取答案
1# 获取重名最多的姓名和次数
2top_name, top_count = most_common[0]
3
4print(f'重名最多的人: {top_name}')
5print(f'出现次数: {top_count}')
6print(f'答案: {top_name}{top_count}')
输出:
重名最多的人: 刘红梅
出现次数: 7
答案: 刘红梅7
Step 4: 验证答案
为了确保答案正确,我们可以验证所有叫"刘红梅"的记录:
1print('验证:所有叫"刘红梅"的记录')
2print('=' * 80)
3
4with open('#U5c45#U6c91#U4fe1#U606f#U8868.csv', 'r', encoding='utf-8-sig') as f:
5 reader = csv.DictReader(f)
6 count = 0
7
8 for row in reader:
9 try:
10 name = base64.b64decode(row['姓名']).decode('utf-8')
11 if name == '刘红梅':
12 count += 1
13 id_card = base64.b64decode(row['身份证号']).decode('utf-8')
14 phone = base64.b64decode(row['手机号码']).decode('utf-8')
15 address = base64.b64decode(row['家庭住址']).decode('utf-8')
16 print(f'{count}. 序号:{row["序号"]:>4} | 身份证:{id_card} | 手机:{phone}')
17 except:
18 continue
19
20print(f'确认:刘红梅 出现了 {count} 次')
输出:
验证:所有叫"刘红梅"的记录
================================================================================
1. 序号: 320 | 身份证:360429199301219709 | 手机:13242965575
2. 序号: 461 | 身份证:654224200208144330 | 手机:15145128603
3. 序号: 664 | 身份证:513422194903038431 | 手机:15835846265
4. 序号: 785 | 身份证:360402196106309326 | 手机:14573029873
5. 序号:1822 | 身份证:45042219530907884X | 手机:15654482963
6. 序号:1880 | 身份证:440701199811034851 | 手机:13170093945
7. 序号:1964 | 身份证:411282194701306231 | 手机:13714155998
================================================================================
确认:刘红梅 出现了 7 次
验证通过:确实有7个不同的人都叫"刘红梅"(身份证号和手机号都不同)
完整解题脚本
1#!/usr/bin/env python3
2import base64
3import csv
4from collections import Counter
5
6def solve():
7 # 读取CSV并解码所有姓名
8 names = []
9
10 with open('#U5c45#U6c11#U4fe1#U606f#U8868.csv', 'r', encoding='utf-8-sig') as f:
11 reader = csv.DictReader(f)
12
13 for row in reader:
14 try:
15 name_encoded = row['姓名']
16 name = base64.b64decode(name_encoded).decode('utf-8')
17 names.append(name)
18 except:
19 continue
20
21 print(f'总共有 {len(names)} 条记录')
22 print()
23
24 # 统计姓名出现次数
25 name_counter = Counter(names)
26
27 # 找出出现次数最多的姓名
28 most_common = name_counter.most_common(10)
29
30 print('出现次数最多的前10个姓名:')
31 print('=' * 60)
32 for name, count in most_common:
33 print(f'{name}: {count} 次')
34
35 print()
36 print('=' * 60)
37 top_name, top_count = most_common[0]
38 print(f'重名最多的人: {top_name}')
39 print(f'出现次数: {top_count}')
40 print()
41 print(f'答案: {top_name}{top_count}')
42
43 return f'{top_name}{top_count}'
44
45if __name__ == '__main__':
46 answer = solve()
运行脚本:
1python3 solve.py
一行命令解题
如果想要快速获取答案:
1python3 -c "
2import base64, csv
3from collections import Counter
4names = []
5with open('#U5c45#U6c11#U4fe1#U606f#U8868.csv', 'r', encoding='utf-8-sig') as f:
6 for row in csv.DictReader(f):
7 try: names.append(base64.b64decode(row['姓名']).decode('utf-8'))
8 except: pass
9top = Counter(names).most_common(1)[0]
10print(f'答案: {top[0]}{top[1]}')
11"
Flag
刘红梅7
答案验证
7个叫"刘红梅"的人分别是:
| 序号 | 身份证号 | 手机号 | 住址 |
|---|---|---|---|
| 320 | 360429199301219709 | 13242965575 | 福建省合肥县高明王街86号12号楼2678室 |
| 461 | 654224200208144330 | 15145128603 | 安徽省秀梅县海陵刘街58号 |
| 664 | 513422194903038431 | 15835846265 | 河北省东县南溪北镇街61号7号楼1536室 |
| 785 | 360402196106309326 | 14573029873 | 青海省兴安盟市崇文杨街59号 |
| 1822 | 45042219530907884X | 15654482963 | 北京市红霞市沈河荆门街32号 |
| 1880 | 440701199811034851 | 13170093945 | 浙江省广州县怀柔潮州路19号15号楼1820室 |
| 1964 | 411282194701306231 | 13714155998 | 北京市贵阳县高明王街86号 |
可以看到,这7个人的身份证号、手机号、住址都不同,是真正的7个不同的人。
数据应急(第一题)
题目名称:磁盘取证 - 合同文件恢复
题目类型:数字取证 (Digital Forensics)
难度:中等
题目描述:
黑客在攻击时,为了对公司造成更大的破坏,直接删除了磁盘中的文件。但好在系统有自动的磁盘备份计划,保留了一个备份磁盘。请你通过技术手段,恢复出黑客删除的文件。
答案要求:
请找出删除的文件中的一个合同文件,提交合同编号。
例:如果合同编号为HT-2023-003085,则最终提交答案为:HT-2023-003085
附件:disk.img (1GB 磁盘镜像文件)
解题思路
这是一道典型的数字取证题,需要:
- 识别磁盘镜像的文件系统类型
- 使用数据恢复工具恢复已删除的文件
- 在恢复的文件中找到合同文件
- 提取合同编号
解题步骤
Step 1: 磁盘镜像基础分析
首先查看磁盘镜像的基本信息:
1file disk.img
输出:
disk.img: DOS/MBR boot sector, code offset 0x3c+2, OEM-ID "mkfs.fat",
sectors/cluster 32, reserved sectors 32, root entries 512, Media descriptor 0xf8,
sectors/FAT 256, sectors/track 63, heads 64, sectors 2097144 (volumes > 32 MB),
serial number 0xdd894a27, unlabeled, FAT (16 bit)
关键信息:
- 文件系统类型:FAT16
- 卷标:unlabeled(无卷标)
- 总扇区数:2097144
- 序列号:0xdd894a27
Step 2: 查看磁盘镜像十六进制头部
1xxd disk.img | head -20
输出分析:
00000000: eb3c 906d 6b66 732e 6661 7400 0220 2000 .<.mkfs.fat.. .
00000010: 0200 0200 00f8 0001 3f00 4000 0000 0000 ........?.@.....
00000020: f8ff 1f00 8000 2927 4a89 dd4e 4f20 4e41 ......)'J..NO NA
00000030: 4d45 2020 2020 4641 5431 3620 2020 0e1f ME FAT16 ..
关键发现:
- 字节 0x00-0x02:
EB 3C 90- FAT引导跳转指令 - 字节 0x03-0x0A:
mkfs.fat- OEM标识 - 字节 0x36-0x3D:
FAT16- 文件系统类型确认
Step 3: 检查文件系统UUID
1sudo blkid disk.img
输出:
disk.img: SEC_TYPE="msdos" UUID="DD89-4A27" BLOCK_SIZE="512" TYPE="vfat"
确认文件系统为 VFAT (FAT16),块大小为512字节。
Step 4: 尝试查看可读字符串
1strings disk.img | head -100
输出中的关键线索:
mkfs.fat
NO NAME FAT16
IN-SE~1ZIP
_____~1PDF
WIN-SERVER-PC-20251202-122722.raw
发现:
- 存在PDF文件的8.3短文件名格式:
_____~1.PDF - 存在一个RAW文件引用
- 文件名被删除后显示为下划线
Step 5: 使用Foremost恢复删除的文件
Foremost是一个基于文件头和文件尾特征的数据恢复工具(文件雕刻技术)。
1# 创建输出目录
2mkdir recovered_files
3
4# 运行foremost恢复
5foremost -i disk.img -o recovered_files -v
Foremost工作原理:
- 扫描磁盘镜像中的二进制数据
- 识别已知文件类型的文件头(如PDF的
%PDF-) - 识别文件尾(如PDF的
%%EOF) - 提取完整的文件内容
输出:
Foremost version 1.5.7 by Jesse Kornblum, Kris Kendall, and Nick Mikus
Audit File
Foremost started at Sun Dec 28 01:32:21 2025
Invocation: foremost -i disk.img -o recovered_files -v
Output directory: /home/kali/Desktop/DemoDir/recovered_files
Configuration file: /etc/foremost.conf
Processing: disk.img
|------------------------------------------------------------------
File: disk.img
Start: Sun Dec 28 01:32:21 2025
Length: 1024 MB (1073741824 bytes)
Num Name (bs=512) Size File Offset Comment
*0: 00351776.pdf 8 KB 180109312
**********|
Finish: Sun Dec 28 01:32:55 2025
1 FILES EXTRACTED
pdf:= 1
------------------------------------------------------------------
Foremost finished at Sun Dec 28 01:32:55 2025
关键信息:
- 成功恢复 1个PDF文件
- 文件大小:8 KB
- 文件偏移:180109312 字节(约172 MB处)
- 文件名:
00351776.pdf(Foremost自动命名,基于扇区号)
计算文件位置:
- 扇区号:351776
- 字节偏移:351776 × 512 = 180109312 字节
- 位置:~172 MB
Step 6: 查看恢复的文件
1ls -R recovered_files/
输出:
recovered_files/:
audit.txt pdf
recovered_files/pdf:
00351776.pdf
文件结构:
audit.txt- Foremost的审计日志pdf/- 恢复的PDF文件目录00351776.pdf- 恢复的合同文件
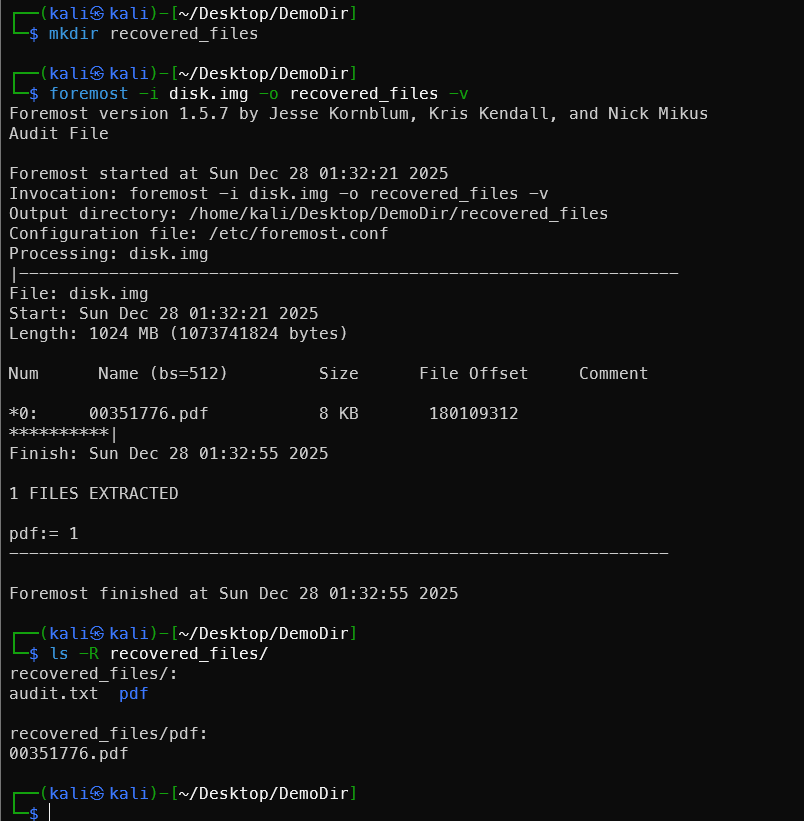
Step 7: 提取合同编号
打开恢复的PDF文件:
1# 方法1: 直接打开PDF查看
2xdg-open recovered_files/pdf/00351776.pdf
3
4# 方法2: 转换为文本后搜索
5pdftotext recovered_files/pdf/00351776.pdf - | grep "HT-"
6
7# 方法3: 使用strings搜索
8strings recovered_files/pdf/00351776.pdf | grep "HT-"
在PDF中发现合同编号:

HT-2025-001234
Step 8: 验证答案格式
合同编号格式:HT-YYYY-NNNNNN
HT: 合同类型标识2025: 年份001234: 六位合同序号
Flag: HT-2025-001234
数据溯源- 【题目1】证书合成
请根据题目提供的证书关键参数,合成私钥解密证书。请选手找到id为285的参数合成的证书(参考附件:params.csv),可以解密哪个流量包(参考附件:pcap.zip)。并将其流量包名称作为答案提交。【答案标准】若id为285的参数合成证书,可以解密"“UT5NHVWo2Z.pcap”",则答案提交为UT5NHVWo2Z.pcap的32位小写MD5值如7cb41b100d1cfbcbd1de1d795dac3fcb
题目分析
题目要求:
- 根据params.csv中id=285的参数合成RSA私钥
- 使用该私钥解密pcap.zip中的流量包
- 找出能被成功解密的流量包文件名
- 提交该文件名的MD5值作为答案
解题步骤
1. 提取ID=285的RSA参数
从params.csv中找到:
id: 285
e: 65537
p: 177264302295959185550899884811457697789837321132319354039496340545988969470422347313577084568610012957139649359576035974322283705879187577664768699213211347033624840318251940972496063336844685896882713624561971974788692556498019960846465311267474369690812099681875735569564330504277517754796899917257323134723
q: 143990163909936129648804807321551478733567016733642335522156625973321506509458427490929508866189002322826874210961910641865602374675333206288577734876005828016379170951078934469472423840724164310343028554942665656763806178050620857070820746559094989518930589089970082522430002916286799917078785172333647028571
2. 计算RSA密钥参数
使用RSA算法计算:
- n = p × q
- φ(n) = (p-1) × (q-1)
- d = e^(-1) mod φ(n)
计算结果:
n = 25524315942975630524902164348980646615415631379067906424905092637569433934236415697372635457461090451139209839638834636903322814809175304746826901103004216102634794552592149840624150935097695947885611303063109481472573238304773329443506200495854657482651549528147796059266681963958098875144795832902194879880482303139612778003682586782728535759095884982208105029514574602777436707784410218940597817232989310469845223163728817066720212125675003809485140708725052901029868743431319305493958381372040484786766296673968301385185624931088751230885265032642815808366813676365040639645753384044321228415112355245904063170833
d = 722845574105661996341279232062927508403061047035263047204233515957838616078593581249120518318625873587658474790876559593703818366507917140090494353528172255161056787610220640313081528534130699898922663205290617477350137026315810907535399974370298370200059141008015464333108957155595030475437402778071527489167629069652916280419064485102236863714459375252132658482271427695730385678764768730893774682537210856041852181896672956592276075190253085972611046793782307817242610172767299787547389163753900144645425776915705020473062273536757021628523871664234759138128442757113837813811691074624911520811865965944689268993
3. 生成RSA私钥
使用Python的pycryptodome库构造RSA密钥对象并导出PEM格式私钥。
4. 测试解密流量包
使用tshark工具配合生成的私钥对pcap.zip中的500个流量包进行TLS解密测试。
解密命令:
1tshark -r <pcap_file> \
2 -o "tls.keys_list:0.0.0.0,443,http,id285_key.pem" \
3 -Y "http" \
4 -T fields \
5 -e http.request.uri
5. 结果
经过测试,发现只有 mAqY0WRHsV.pcap 能被成功解密。
解密后可以看到HTTP流量:
POST /api/v1/user/profile
这证明该证书与此流量包中的TLS会话匹配。
答案
文件名: mAqY0WRHsV.pcap
MD5值: 1f5c34eab5696a300afff7452b7f7e6a
验证
1$ echo -n "mAqY0WRHsV.pcap" | md5sum
21f5c34eab5696a300afff7452b7f7e6a
🔔 想要获取更多网络安全与编程技术干货?
关注 泷羽Sec-静安 公众号,与你一起探索前沿技术,分享实用的学习资源与工具。我们专注于深入分析,拒绝浮躁,只做最实用的技术分享!💻
马上加入我们,共同成长!🌟
👉 长按或扫描二维码关注公众号
直接回复文章中的关键词,获取更多技术资料与书单推荐!📚

